摘要:本报告基于METG、Amdahl定律、Brooks定律及认知负荷理论的理论推导,结合阿里、腾讯、Google、亚马逊等12家大厂的案例分析与心理学实证研究,探讨研发任务颗粒度拆解这一复杂工程实践。核心发现:4-12小时(0.5-1.5天) 是人类开发者任务粒度的"黄金区间",该结论得到系统效率、神经科学、流程效率三重约束的交叉验证;AI协作场景下粒度应进一步压缩至 30-90分钟。主要建议包括:以1天为人类开发基准粒度、以90分钟为AI协作原子单位、采用垂直切片而非水平切片、通过四问法验证拆解充分性。需注意,本报告结论主要适用于迭代式开发的功能交付场景,探索性研究、创意设计、深度重构等场景需差异化处理(详见8.6节)。
引言:软件研发范式演进
在深入探讨任务颗粒度之前,有必要先理解软件研发模式的宏观演变。从历史视角看,软件研发经历了从工程范式到开源/群智范式,再到当前正在发生的 智能范式(Agentic AI) 的深刻转变。这种转变不仅改变了代码的生产方式,更从根本上重构了需求管理、质量保障与效率提升的核心逻辑。
三大范式的演进脉络
工程范式(1960s-1990s)
传统工程范式植根于大型机时代,其核心假设是"需求在先、开发在后",强调在确定性场景下通过强组织管理来降低不确定性。在这种范式下:
软件质量被严格定义为"代码对需求规格说明书的符合程度"
效率提升依赖于人力与时间投入的优化
项目成功取决于前期需求分析的完备性
然而,随着软件系统复杂性呈指数级增长,工程范式在应对需求不确定性时的脆弱性日益凸显。
开源范式(1990s-2010s)
开源范式颠覆了"需求先行"的逻辑,转而基于开发者的个人理解进行创作,质量通过社区同行评审与口碑来背书。其核心机制包括:代码公开、分布式协作、邮件列表讨论、层级维护者审核制度。学术界后来将这种大规模协作模式抽象为"群智范式"。
智能范式(2020s-)
当前最前沿的智能范式——AI代理范式(Agentic AI),正在推动AI从"被动工具"向"主动协作伙伴"的角色跃迁。在这种范式下,AI不再只是回答问题的对话框,而是能够自主感知环境变化、动态调整策略、并执行端到端任务的智能系统。
范式演进对比表
范式演进对任务拆解的影响
理解这一演进脉络对于把握任务拆解的本质至关重要:
工程范式下,任务拆解是自上而下的"分解工程",强调完备性和可预测性
开源范式下,任务拆解是动态涌现的"协作契约",强调独立性和可并行性
智能范式下,任务拆解正在成为"人机共创"的过程,AI能够自主生成子任务并验证逻辑一致性
在智能范式下,技术选型周期可以从数周压缩至数天,这种效率提升得益于AI对海量技术特性的快速分析与场景匹配能力。但与此同时,评估AI能力的重点也从简单的"代码生成量"转向了"自主架构决策的推理质量"、"自然语言交互的精准度"以及"端到端流程的自动化程度"。
一、任务颗粒度的理论基石
上一节展示了软件研发范式的演进——从工程范式到智能范式,任务拆解的方式和最优粒度都在变化。但无论范式如何演进,有一些基本原理是恒定的:系统并行的极限、沟通的代价、人脑的容量限制……这些"第一性原理"决定了任务粒度的底层逻辑。本章将从这些理论基石出发,为后续章节的实践指南奠定科学基础。
任务颗粒度(Task Granularity)定义了将复杂研发目标分解为可执行工作单元的细致程度。这个看似简单的概念,背后却蕴含着深刻的系统工程原理。
1.1 最小有效任务颗粒度(METG)与行政损耗
概念解释
在高性能计算领域,"最小有效任务颗粒度(Minimum Effective Task Granularity, METG)"用于界定系统效率维持在阈值以上的最小任务时长。
开发类比:PR拆分的两难
想象你在做一个用户模块的重构:
一个巨型PR(粗粒度):2000行代码改动,评审者看到就头大,来回评审3天,期间你不断rebase解决冲突
50个微型PR(过细粒度):每个PR只改一个变量名,光是"创建分支→提交→等审核→合并"的流程就耗尽了一天
恰到好处:每个PR 100-300行,聚焦一个完整的小功能,评审者15分钟看完,当天合并
在人力研发系统中,METG对应于:在不产生过度会议成本、状态同步开销和上下文切换损失的前提下,任务能被拆分的最小限度。
效率公式
研发产出的有效率可表示为:
有效率 = 净开发时间 / (净开发时间 + 同步时间 + 切换损耗)
其中:
净开发时间:真正写代码、思考架构的时间
同步时间:状态更新、站会和沟通时间
切换损耗:由于任务过细导致的上下文切换损耗
具体数据参考:
每次任务状态同步(站会汇报、更新看板)约需 15-30分钟
一次深度上下文切换的恢复时间约需 23分钟(加州大学Irvine研究,详见1.5节认知负荷理论)
如果任务粒度为2小时,每天需切换4次,仅切换损耗就可能超过1.5小时
METG的技术系统视角:从计算到架构
上述"效率公式"描述的是人力协作中的损耗,但METG理论的根源其实来自一个更底层的领域——高性能计算(HPC)。理解这个源头有助于我们从系统工程的视角审视任务拆解:无论是CPU调度进程,还是团队分配工作,底层逻辑惊人地相似。
斯坦福大学的Alex Aiken教授等学者将 METG(50%) 定义为:系统在维持至少50%效率的前提下,所能处理的最小任务时长。
直观理解:如果任务执行时间过短,系统用于调度、同步和通信的开销(Overhead)将超过实际计算工作(Useful Work),导致整体吞吐量崩塌。这与研发团队的处境如出一辙——任务拆得太细,"开会同步"的开销就会吞噬"写代码"的时间。
不同并行系统的METG基准值对比:
对软件架构的启示:在100个节点以上的分布式系统中,100微秒(100μs) 是大多数系统能够高效运行的任务颗粒度底线。低于此阈值,系统性能将急剧下降。
延伸类比:微服务颗粒度的权衡
💡 本小节为延伸阅读:将METG思维应用到系统架构设计,帮助理解"颗粒度权衡"是一个普适原理。如急于了解任务拆解主线,可跳至1.2节。
从HPC系统的METG回到我们更熟悉的领域——如果把"任务颗粒度"的思维应用到系统架构设计上,会发现同样的规律在起作用。微服务架构本质上就是把"单体应用"拆解成多个"可独立部署的任务单元",这与把大需求拆成小任务是同一种思维模式。
微服务颗粒度的确定是架构设计的核心挑战:
"纳米服务"反模式:当服务被拆分得过细时,会引入:
网络延迟累积:原本一次内存调用变成多次网络往返
分布式事务复杂性:跨服务的数据一致性难以保证
服务治理开销:每个服务都需要监控、日志、熔断、限流
优秀的微服务设计应追求在 高内聚(High Cohesion) 与 低耦合(Low Coupling) 之间找到平衡点,确保服务规模与其业务价值和运维成本相匹配。
来源:Task Bench - Stanford Legion、Defining and measuring microservice granularity - PMC
1.2 Amdahl定律:并行的天花板
METG告诉我们任务不能拆得太细,否则开销会吞噬效率。但如果任务足够大,我们能通过增加人手来加速吗?Amdahl定律给出了令人沮丧的答案:无论投入多少人力,系统中的串行部分决定了加速的天花板。
核心原理
Amdahl定律指出:系统的最大加速比受限于其无法并行化的顺序执行部分。
用公式表示:
加速比 = 1 / (串行占比 + 可并行占比 / 人数)
其中"串行占比"是必须顺序执行的工作比例,"可并行占比 = 1 - 串行占比"。
100小时项目模型:一个简单计算
假设一个项目总工作量为100小时:
20小时必须顺序执行(核心数据模型定义、API契约制定、架构评审)
80小时可并行(功能开发、测试编写、文档撰写)
关键洞察:即使投入无限人力,项目也无法在20小时内完成。这解释了为何盲目堆人无法缩短交付周期的底层逻辑。
开发类比:微服务启动依赖链
你的电商系统有三个服务要部署:
用户服务:无依赖,部署需要10分钟
商品服务:无依赖,部署需要10分钟
订单服务:必须等用户服务和商品服务都Ready后才能启动,自身部署需要10分钟

串行瓶颈演示 (微服务启动依赖)
无论你给用户服务和商品服务配多少资源,整个系统最快也要20分钟才能就绪——因为订单服务的依赖等待是"串行瓶颈"。
在研发中,这类"串行任务"包括:
核心数据模型定义(下游服务必须等它)
API契约制定(前后端必须先对齐)
架构方案评审(编码必须等评审通过)
关键依赖库的选型(功能开发必须等选型确定)
1.3 Brooks定律与沟通开销:人越多越慢?
Amdahl定律揭示了串行瓶颈的天花板,但这还不是全部坏消息。在真实的研发团队中,加人不仅受限于串行部分——每增加一人,沟通路径就会呈指数级增长。Brooks定律将这个残酷的现实推向了更极端的结论。
《人月神话》的警告
1975年,Fred Brooks在经典著作《人月神话》中提出了著名的Brooks定律:
"Adding manpower to a late software project makes it later." (向一个延期的软件项目增加人力,只会让它更加延期。)
沟通路径公式
团队内部潜在的沟通路径数量为:
沟通路径数 = 人数 × (人数 - 1) / 2
沟通熵:大团队的隐形杀手
这种沟通路径的爆炸性增长产生了所谓的 "沟通熵"(Communication Entropy) —— 团队中信息混乱度的度量。
沟通熵的具象化理解:
一个50人的大型研发组织存在1225个潜在沟通渠道
如果每个渠道每周只产生1条需要同步的信息,就意味着每周有1225条信息在团队中流动
每个人需要处理的信息量 = 总信息量 × 与自己相关的比例
过多的沟通需求会产生巨大的认知负担,消耗开发者原本用于深度思考的时间。根据《DevData 2025研发效能基准报告》,大公司开发者每周比小公司开发者多花2.5小时在开会上(约每月10小时),这被戏称为 "协调税"(Coordination Tax)。
这也是为什么小型团队往往表现出更高的灵活性与人均吞吐量,而大型团队则容易陷入"虚假繁荣" —— 看起来人很多、会很多、产出却不成比例。
经典案例:9个女人不能在1个月内生出孩子
Brooks在书中用这个著名的比喻说明:某些工作本质上无法通过增加人手来加速。
更重要的是,新人加入还会带来额外开销:
培训成本:现有成员需要花时间带新人
沟通成本:每增加一人,潜在沟通路径就增加n条
协调成本:需要更多会议来对齐信息
在研发中的典型表现:
3人小组:站会10分钟,大家都清楚彼此在做什么
10人团队:站会30分钟,开始出现"我不知道他那块的进度"
20人团队:站会变成汇报会,真正的沟通要靠会后单独拉群
这就是为什么亚马逊坚持"双披萨团队"——规模越大,沟通开销呈指数级增加。
通用可扩展性定律(USL)
Neil Gunther提出的 USL(Universal Scalability Law) 在Amdahl定律基础上增加了"协调惩罚"因素:
实际产能 = 人数 / (1 + 串行开销×(人数-1) + 协调开销×人数×(人数-1))
当团队超过某个"峰值效率点"后,每增加一人,整体效率反而下降。
1.4 效能U型曲线
到这里,我们已经收集了三条相互制衡的约束:METG告诉我们任务不能太细(切换开销),Amdahl定律告诉我们并行有天花板(串行瓶颈),Brooks定律告诉我们人多反而更慢(沟通开销)。把这些约束叠加在一起,就会形成一条关于任务粒度的U型曲线——太细或太粗都有代价,最优解在中间某处。
本节先从管理实践角度给出黄金区间的初步结论,接下来两节(1.5认知负荷、1.6精益视角)将从神经科学和流程效率两个更深维度验证这个结论的合理性。
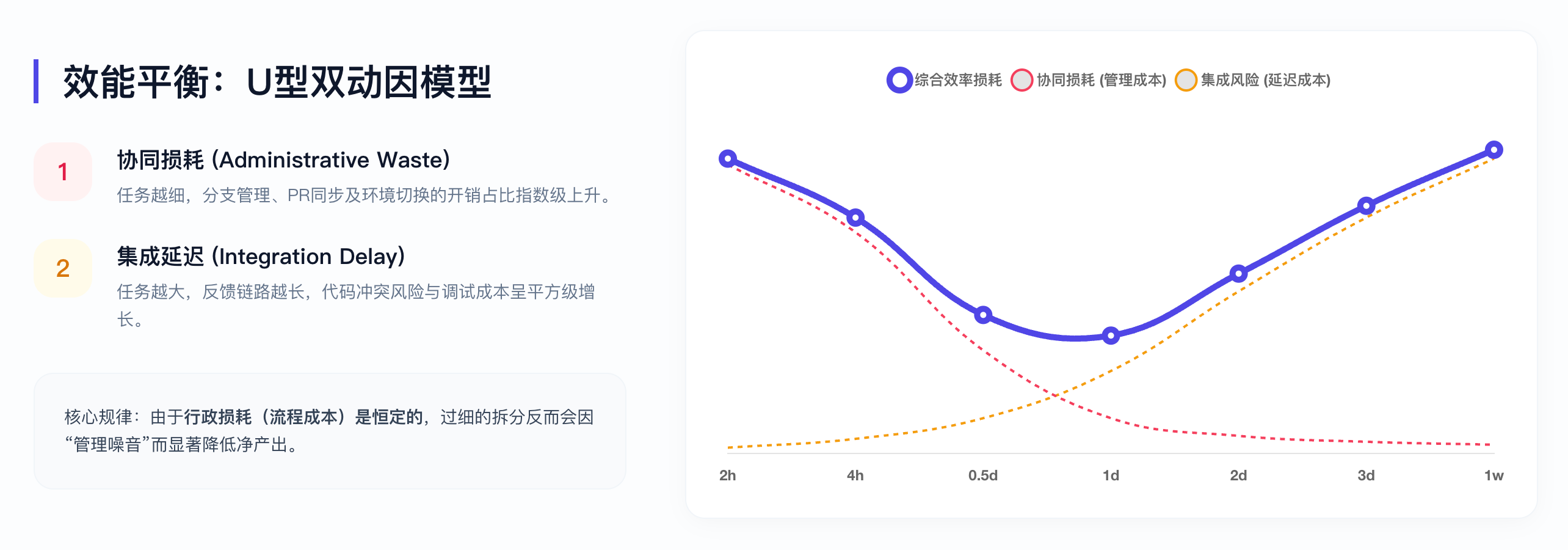
效能平衡:U型双动因模型
U型曲线的形态解读:
横轴为任务粒度(从左到右由细变粗),纵轴为总成本/效率损失。曲线呈现U型:
左侧陡峭上升区(粒度过细):切换成本(T_switch)随粒度变小而指数上升,表现为频繁的上下文切换、PR审核排队、站会汇报冗长
右侧缓慢上升区(粒度过粗):风险成本(T_risk)随粒度变大而线性上升,表现为进度黑盒、估时偏差、集成冲突
谷底区域(4-12小时):两种成本的叠加达到最小值,这就是"黄金区间"
两条曲线的交叉点(约0.5-1.5天)即为最优解——在此区间,切换开销尚可接受,风险暴露足够及时。
过细拆解的代价(Fine-grained)
当任务粒度小于4小时:
上下文切换损耗(T_switch)指数级上升
开发者频繁在分支切换和PR审批中穿梭
每个任务的"仪式成本"(创建分支、提PR、等审核、合并)占比过高
症状:开发者抱怨"一天都在开会和等审核"
过粗拆解的代价(Coarse-grained)
当任务粒度大于3天:
产生"进度黑盒",管理者无法感知真实进展
风险在水面下累积,直到周末集成时集中爆发
估时准确性急剧下降(误差可达50%以上)
症状:周五下午频繁出现"惊喜"
黄金区间
开发类比:Sprint任务的"刚刚好"
想象三种Sprint计划方式:
对于人类开发者,建议将单个子任务控制在 4-12小时(0.5-1.5个工作日):
足够小:每天都能感受到"完成"的成就感,看板有流动
足够大:有意义的工作单元,不会被"创建分支→提PR→等审核"的仪式成本淹没
可估算:1天内的任务,估时误差通常在20%以内
可验证:当天或次日即可获得CI/CD和评审反馈
"即时清零"的交付节奏:
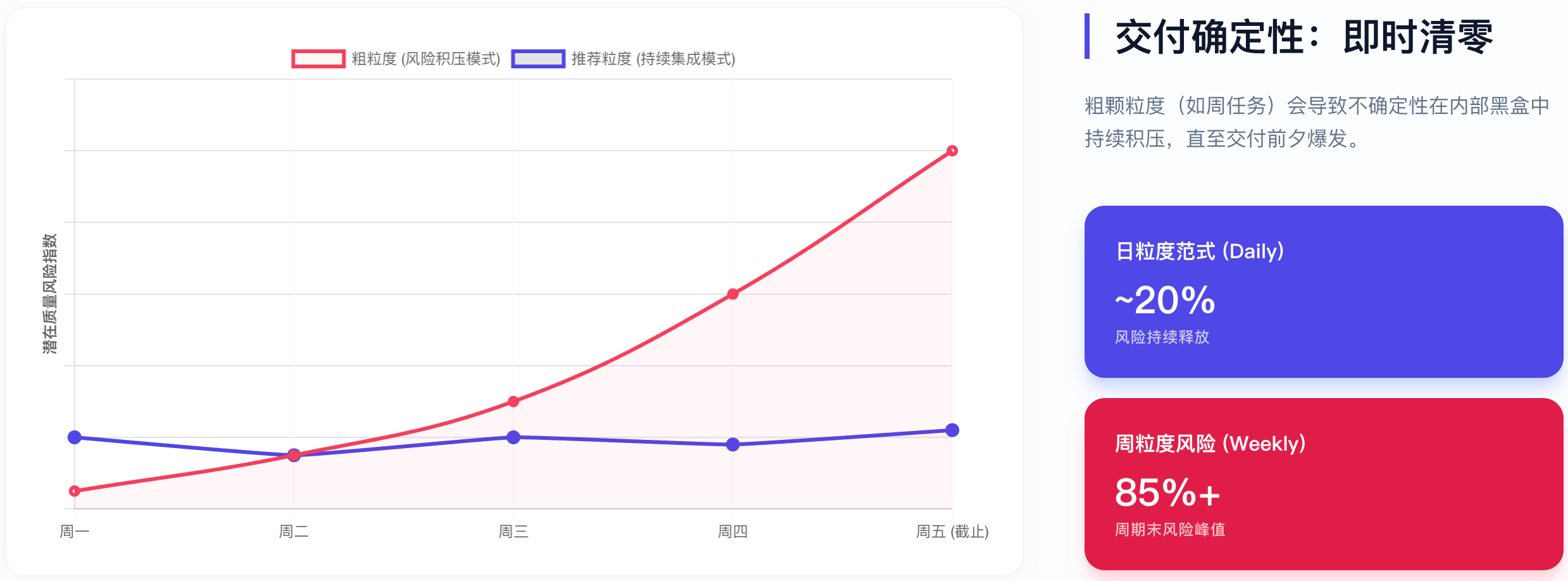
交付确定性:即时清零
上图展示了两种不同粒度策略下的交付确定性对比。横轴为时间(以天为单位),纵轴为累计完成任务数:
细粒度策略(0.5-1天/任务):曲线呈平稳阶梯状上升,每天都有1-2个任务从"进行中"变为"已完成",团队每日都能感受到进展,问题当天暴露当天解决
粗粒度策略(5-7天/任务):曲线长期平坦,在第5-7天突然跃升,期间进度不可见,风险累积,最终可能因集成问题导致延期
"即时清零"意味着:每天结束时,当天启动的任务应尽量完成,不留"半成品"过夜。这不仅是效率要求,更是风险管理——未完成的任务像信用卡债务,会产生"利息"(上下文遗忘、代码冲突、心理负担)。
1.5 认知负荷理论:任务拆解的神经科学解释
U型曲线告诉我们"4-12小时"是黄金区间,但为什么是这个数字?前面的分析基于系统效率和管理实践,但还有一个更深层的答案藏在我们的大脑中。认知负荷理论(Cognitive Load Theory, CLT)从神经科学角度揭示:这个区间恰好匹配了人类工作记忆的生物学限制。
工作记忆的生物学限制
人类大脑的工作记忆容量是有限的——通常只能同时处理4±1个信息块(Chunks)。这不是能力问题,而是生物学硬约束。
开发场景映射:
当你在实现一个复杂功能时,工作记忆需要同时维持:
当前正在编写的逻辑(1个块)
上下文:这段代码在整个模块中的位置(1个块)
约束:需要满足的接口契约和边界条件(1个块)
目标:这个任务最终要达成的验收标准(1个块)
当任务过于复杂,需要维持的信息块超过4-5个时,大脑就会"溢出"——开始遗忘关键约束、引入逻辑漏洞、产生低级错误。
认知负荷的三种类型
认知负荷理论将大脑承受的负担分为三类,每类对任务拆解有不同的指导意义:
关键洞察:
原生负荷无法消除(复杂问题就是复杂),但可以通过任务拆解将其分摊到多个认知周期
外在负荷是纯粹的浪费,应该尽可能消除
关联负荷是有益的,能帮助开发者建立长期记忆中的"自动化技能"
认知处理的三阶段模型
理解开发者如何处理信息,有助于更好地设计任务粒度。个体认知处理可分为三个阶段:

认知处理三阶段模型
感知记忆(Sensory Memory):捕捉代码语法、UI视觉信息等原始输入,持续时间极短(<1秒)
工作记忆(Working Memory):对信息进行有意识的处理,容量有限(4±1块),是认知瓶颈所在
长期记忆(Long-term Memory):存储经验、设计模式、历史代码细节等知识
开发中的认知流程:当处理复杂逻辑时,开发者需要不断从长期记忆中检索相关设计模式或历史代码细节,这个检索过程本身就会占用工作记忆。因此:
任务过大:需要检索的长期记忆过多,工作记忆被检索任务挤占,无法专注于当前逻辑
任务过小:长期记忆中的模式无法被有效激活,每次都像"从零开始"
上下文切换的认知代价
每一次任务切换都会导致工作记忆中的临时模式崩溃。重新构建这些模式需要付出巨大代价:
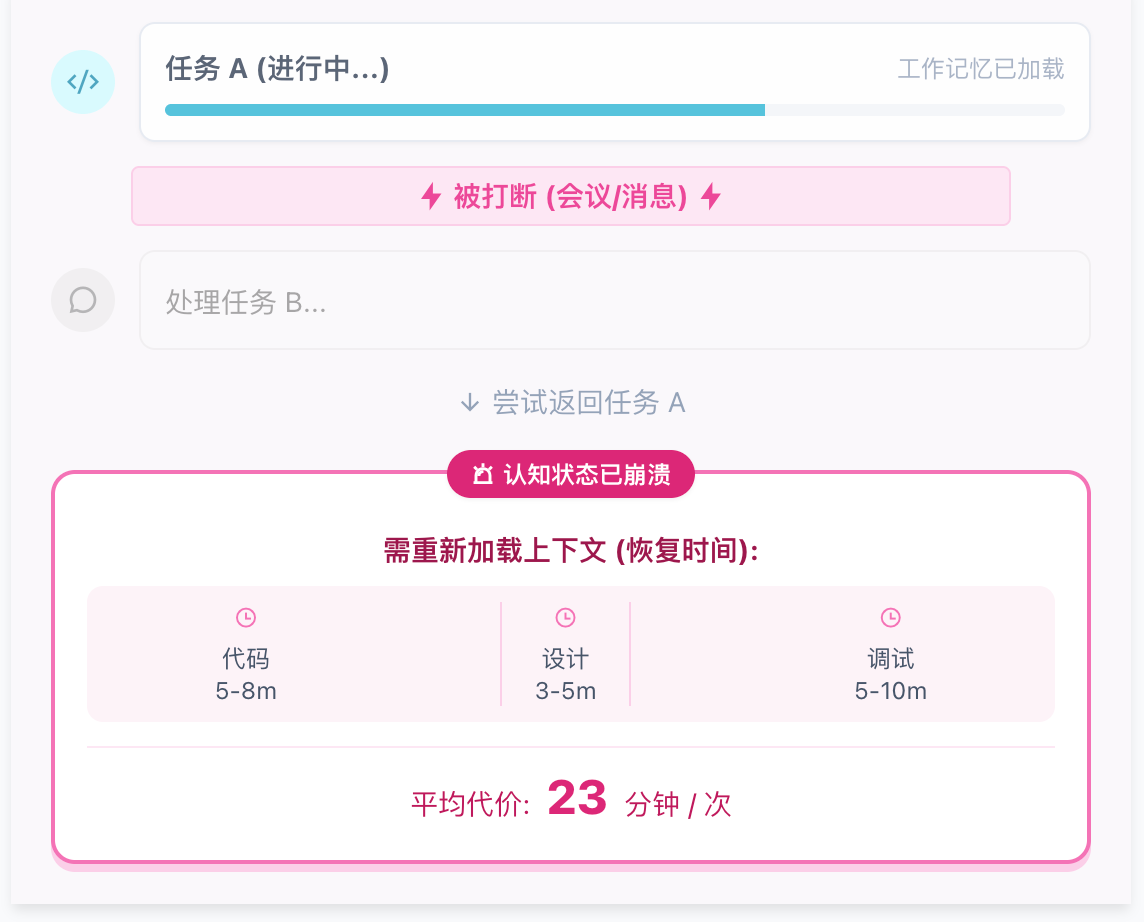
上下文切换的认知代价
实证数据:
加州大学Irvine的Gloria Mark研究发现,被打断后恢复到原有专注状态平均需要23分钟
微软研究院的调查显示,开发者平均每11分钟就会被打断一次
这意味着一个频繁被打断的开发者,可能永远无法进入深度工作状态
注意力残留:为什么23分钟才能恢复?
注意力残留(Attention Residue) 是Sophie Leroy提出的概念,解释了为什么任务切换的代价如此高昂:
当大脑从任务A转移到任务B时,部分认知带宽仍被"锁定"在任务A上,导致处理任务B时的智力表现打折。
这就像是浏览器中打开了太多标签页——即使你只在看其中一个,其他标签页仍在后台占用内存。
现代研发环境的碎片化:
在今天的开发环境中,数字干扰(邮件、Slack消息、JIRA通知)极为频繁:
知识工作者平均每90秒就会切换一次应用
如果每天被中断5次,仅恢复深度聚焦的时间就将消耗近2小时
这占到了有效工作时间的四分之一
认知负荷与注意力损耗的叠加效应:
工具疲劳的具体表现:
在IDE、Jira、Confluence、Slack、邮件之间来回切换
同一信息需要在多个系统中重复录入
工具之间数据不互通,需要人工搬运
这也是为什么现代研发效能工具越来越强调工具链整合和自动化数据采集——减少开发者在"系统同步"上的外在负荷。
认知负荷与4-12小时法则的关联
结论:4-12小时的任务粒度之所以是"黄金区间",是因为它恰好匹配了人类工作记忆的容量限制——既能在单个认知周期内完成,又不会因过于琐碎而被外在负荷淹没。
来源:
Gloria Mark, "The Cost of Interrupted Work", UC Irvine
1.6 精益视角:研发中的七大浪费与任务粒度
认知负荷理论关注的是开发者个体的大脑容量限制,但效率损失不仅发生在"脑内"——大量时间浪费在流程间隙中:等待评审、等待环境、等待需求确认……精益生产理论(Lean)为我们提供了另一个审视任务粒度的视角:提升效能最有效的路径不是"跑得更快",而是"停止做不该做的事"。Mary Poppendieck等人在《精益软件开发》中将制造业的七大浪费(Muda)映射到了软件研发领域,其中多项浪费与任务粒度直接相关。
与任务拆解相关的四大浪费
流动效率:揭示隐藏的等待浪费
流动效率(Flow Efficiency) 是精益理论中的核心指标,定义为:
流动效率 = 实际工作时间 / 总流转时间 × 100%
惊人的发现:通过价值流图分析(Value Stream Mapping),团队往往会震惊地发现——
一个前置时间为10天的任务,实际动手编码的时间可能只有5小时。 剩下的时间全部在"等待"和"移交"中流逝。
典型任务流转时间分解:

揭示隐藏的等待浪费 (流动效率分析)
洞察:在这个例子中,92.7%的时间是浪费。优化流动效率的潜力远大于通过AI辅助编程带来的局部提速。
半成品浪费:任务粒度的隐形杀手
半成品(Work in Progress, WIP) 是精益理论中最被低估的浪费。在软件研发中,半成品包括:
写了一半的代码
提交了但未合并的PR
开发完但未测试的功能
测试通过但未上线的版本
半成品的危害:
不产生价值:代码只有上线才能为用户创造价值
持续消耗精力:需要记住上下文,随时准备继续
增加集成风险:存在时间越长,与主干冲突概率越高
占用认知带宽:未完成的任务会在心理上形成负担(蔡格尼克效应)
任务粒度与半成品的关系:
最佳实践:控制任务粒度在4-12小时,确保:
每天都有任务完成并合并
WIP数量保持在2-3个以内
避免"周五下午的集成噩梦"
上下文切换:多任务并行的代价
精益理论指出,同时处理多个任务会导致每个任务的效率下降:
与任务粒度的关联:
任务粒度过大(>3天):更容易被迫中断去处理其他紧急事务,被动切换
任务粒度过小(<2小时):主动切换频繁,每次切换都有恢复成本
任务粒度适中(4-12小时):有足够的专注时间块,又不会因为任务太长而被迫切换
来源:
Mary & Tom Poppendieck,《精益软件开发》
1.7 本章小结
本章从三个维度论证了"4-12小时"黄金区间:
三个视角殊途同归:4-12小时是效率、能力、流程三重约束的交集。接下来,让我们看看全球顶级大厂如何在实践中验证和落地这一结论。
二、大厂颗粒度准则
顶级大厂通过原子化拆解和组织解耦,在数万人规模下依然保持了敏捷性。以下是各家的具体实践。
2.1 阿里巴巴:2-1-1愿景与INVEST原则
阿里巴巴通过"云效"平台强调"看见"价值流动。
2-1-1目标
INVEST原则详解
阿里要求所有用户故事(User Story)遵循INVEST原则:
半天到两天规则
任务(Task)应保持在 4-16小时:
超过2天:会掩盖阻塞点,风险不可见
小于2小时:行政成本高于产出,得不偿失
2.2 腾讯:TAPD支撑下的层级约束
腾讯强调"反馈驱动"的快速迭代。
3层层级红线
腾讯不建议产生3层以上的父子需求结构:

腾讯 TAPD 层级约束
原因:层级过深会导致:
管理复杂度指数上升
状态同步链条过长
责任归属模糊
缺陷年龄报告
TAPD提供精准的Bug停留时间度量:
创建到分配:平均应<4小时
分配到修复:根据优先级设定SLA
修复到验证:应<24小时
通过分析各状态的停留时间,可以精准定位是修复慢还是验证慢。
工时继承机制
支持子任务工时自动汇总至父需求,倒逼开发者在排期阶段就进行原子化思考。
如果一个Story估时20小时,但拆分出的Task只有12小时,说明遗漏了工作项。
2.3 亚马逊:双披萨团队与所有权逻辑
亚马逊实施"双披萨团队"(Two-Pizza Team)和"单线程领导力"(Single-Threaded Leadership)。
双披萨原则
规则:一个团队的规模应该小到两个披萨就能喂饱(5-10人)。
数学验证:
当团队超过10人,沟通开销就开始反噬生产力。
乐高实验
一项著名的实验显示:
2人组构建同一款乐高人偶的速度远快于4人组
2人组的估时偏差也更小
原因:协调成本在小团队中几乎为零
这个实验直观地证明了:团队规模并非越大越好。当任务本身的协调复杂度超过执行复杂度时,加人反而会拖慢进度。
"You build it, you run it"
亚马逊的任务拆解涵盖从创意到运维的全生命周期:
开发团队不仅写代码,还负责运维
如果服务过大,标准动作是系统拆分而非扩充人手
每个团队对自己的服务拥有完整所有权
2.4 字节跳动:0.5-1天准则与自动化拦截
字节跳动强调极致透明和数据驱动。
理想粒度
建议开发任务拆分为 0.5-1天(4-8小时)。
自动化拦截机制
在飞书项目(Meego)中:
预估工时超过 2天(16小时) 的任务会被系统自动标记异常
标记后必须提供拆解说明或申请例外
这种"硬约束"强制团队在前期就进行深度思考
效能度量体系
字节的效能度量不仅看"做了多少",还看"流动效率":
需求从提出到上线的端到端时间
各阶段的等待时间占比
返工率和缺陷逃逸率
2.5 Google:100行法则
Google在Mono-repo(单一代码仓库)下推崇Small CLs(小型代码变更)。
核心数据
为什么小CL更好?
Google官方文档列出了8个理由:
更快的审核:评审者更容易找到5分钟碎片时间完成小CL审核
更彻底的审核:大变更会让评审者疲劳,重要问题容易被遗漏
更少的Bug:小范围改动更容易推理其影响
更少的浪费:如果方向错误,丢弃的代码更少
更容易合并:停留时间短,冲突概率低
更好的设计:小变更更容易打磨
更少的阻塞:可以在等待审核时继续开发下一个CL
更简单的回滚:如果出问题,定位和回滚都更容易
CL拆分策略
Google推荐的四种拆分方法:
评审者的权力
"Reviewers have discretion to reject your change outright for the sole reason of it being too large." (评审者有权直接拒绝过大的变更,仅以"太大"为由。)
这不是建议,而是规则。
2.6 华为:IPD/IPM与研发云平台
华为是国内最早系统化实践研发效能管理的企业之一,其方法论深受IBM IPD(集成产品开发)影响,并在实践中演化出独特的"16小时原则"。
16小时原则
IPD/IPM体系的任务层级
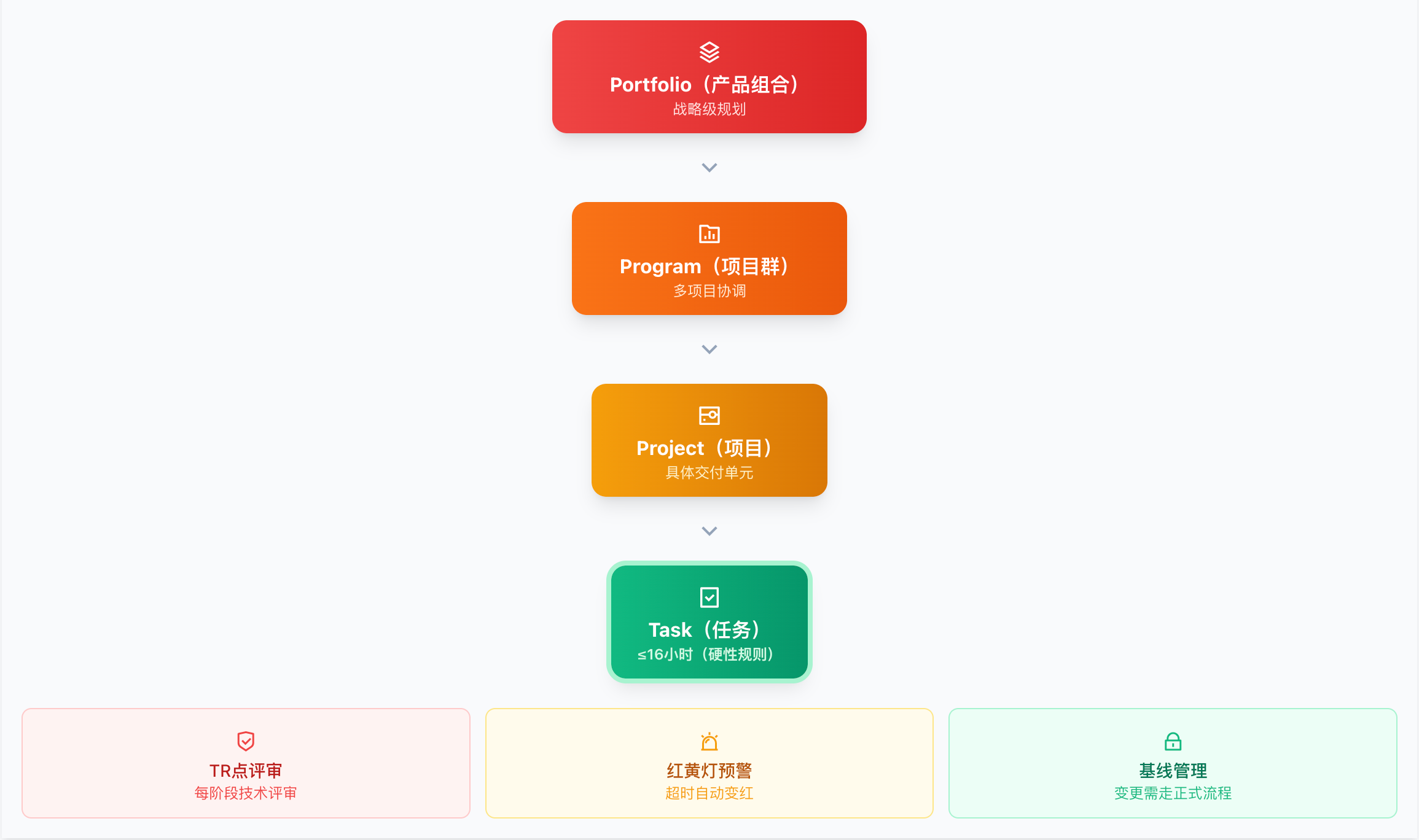
华为IPD/TAPD任务层级结构
华为采用IPD(集成产品开发) 框架,将任务分为四个层级:
Portfolio(产品组合)
└── Program(项目群)
└── Project(项目)
└── Task(任务,≤16小时)
关键实践:
需求评审会(TR点):每个阶段都有技术评审点,确保任务拆解质量
基线管理:任务一旦纳入基线,变更需走正式流程
红黄灯预警:超过预期工时的任务自动变红,强制关注
华为云DevCloud的工时管理
华为云的DevCloud平台内置了工时追踪功能,核心指标包括:
2.7 美团:日清文化与原子化项目
美团是国内"日清文化"的典型代表,其核心理念是:每天都要有可交付的产出。
PDCA驱动的任务管理
美团将复杂项目分解为"原子项目",每个原子项目都遵循PDCA循环:
美团的"三个凡是"原则
凡是能拆的任务都要拆:鼓励细粒度
凡是能并行的任务都要并行:减少串行等待
凡是能自动化的流程都要自动化:减少人工开销
日清看板实践
美团团队普遍使用"日清看板",包含三列:
来源:美团技术团队成本治理实践
2.8 拼多多:熟悉度关联与快速迭代
拼多多以极致的迭代速度著称,其任务拆解哲学可以概括为:熟悉程度决定粒度。
熟悉度-粒度映射
"压强原则"
拼多多推崇"压强原则":在有限时间内集中资源攻克一个点,而不是分散精力做多件事。这与任务粒度的关系是:
任务越聚焦,压强越大
压强越大,突破越快
突破越快,反馈越及时
快速验证文化
2.9 Netflix/Spotify:微服务与Squad模型
作为全球技术领先的互联网公司,Netflix和Spotify在任务拆解上有独特的组织设计。
Netflix:Freedom & Responsibility
Netflix的工程文化以"高度自由+高度责任"著称,其任务拆解特点:
微服务边界即任务边界
Netflix是微服务架构的先驱,其核心原则是:
"You Build It, You Run It"
Netflix要求开发者对自己的代码负全责,从开发到运维:
任务粒度影响:因为要自己运维,开发者会倾向于做小而稳的改动
反馈周期:代码上线后立即收到生产环境反馈
责任闭环:出了问题自己修,不会"甩锅"给运维
Spotify:Squad模型
Spotify发明了著名的"Squad模型",是敏捷组织设计的经典案例:
组织结构
Tribe(部落,<150人)
└── Squad(小队,6-12人,跨职能)
└── Chapter(分会,同职能跨Squad)
└── Guild(公会,兴趣社区)
Squad的任务拆解特点
Spotify的迭代节奏
下图对比了Netflix与Spotify两种组织模型的核心差异:Netflix强调"微服务=团队边界",通过接口契约实现解耦;Spotify则以Squad为基本单元,强调端到端负责和自主决策。两者殊途同归,都实现了"小团队+明确边界+快速迭代"的目标。
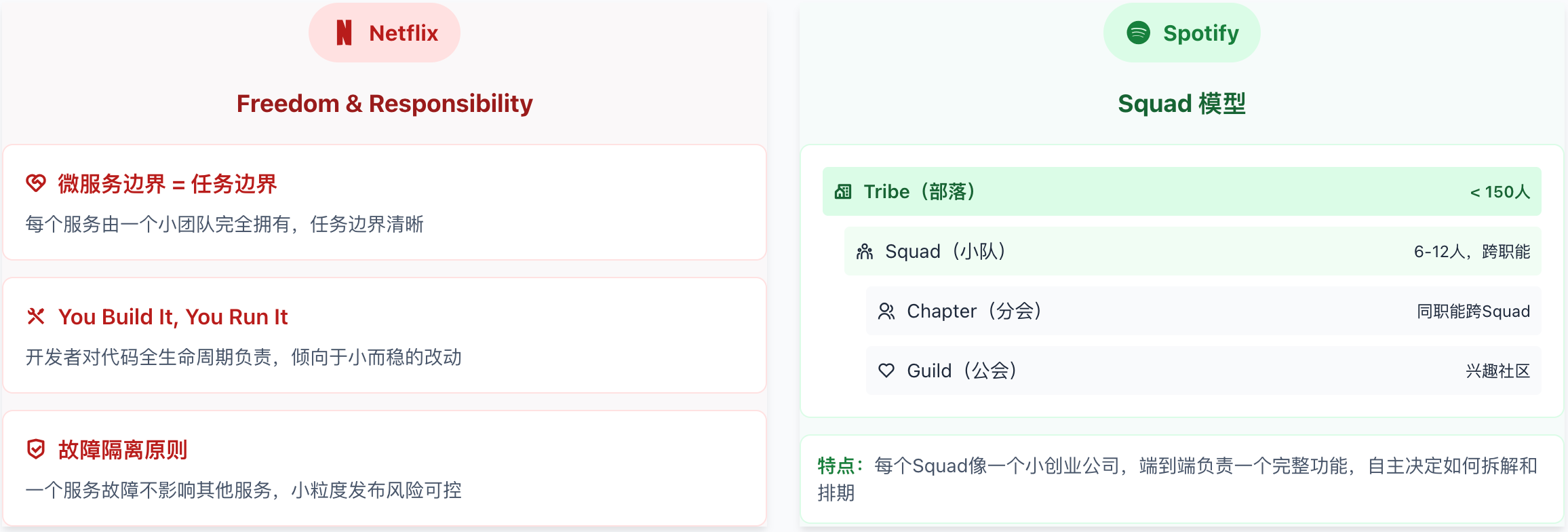
Netflix/Spotify 组织模型对比
来源:
三、全职能差异化拆解指南
前两章从理论和大厂实践两个维度论证了"4-12小时"黄金区间的合理性。但这个区间并非铁律——不同职能的工作性质差异,决定了最优粒度需要因岗制宜。前端开发能快速看到视觉反馈,后端需要考虑事务完整性,算法研究则充满探索性不确定性。本章将这些差异具体化,为各职能提供可操作的拆解基准。
3.1 职能对照表
3.2 职能详解
前端开发(0.5-1天)
拆解原则:以视觉单元或用户交互为边界
示例:实现用户登录页面

前端拆解示例 (视觉/交互边界)
将"登录页面"这个模糊需求拆解为可独立验收的原子任务:
每个任务都是"垂直切片":包含该功能所需的全部代码(组件+逻辑+样式),可独立在浏览器中演示。
特点:前端任务通常能获得即时视觉反馈,适合更细的粒度。
后端开发(1-2天)
拆解原则:以API契约或完整业务逻辑为边界
示例:实现订单服务
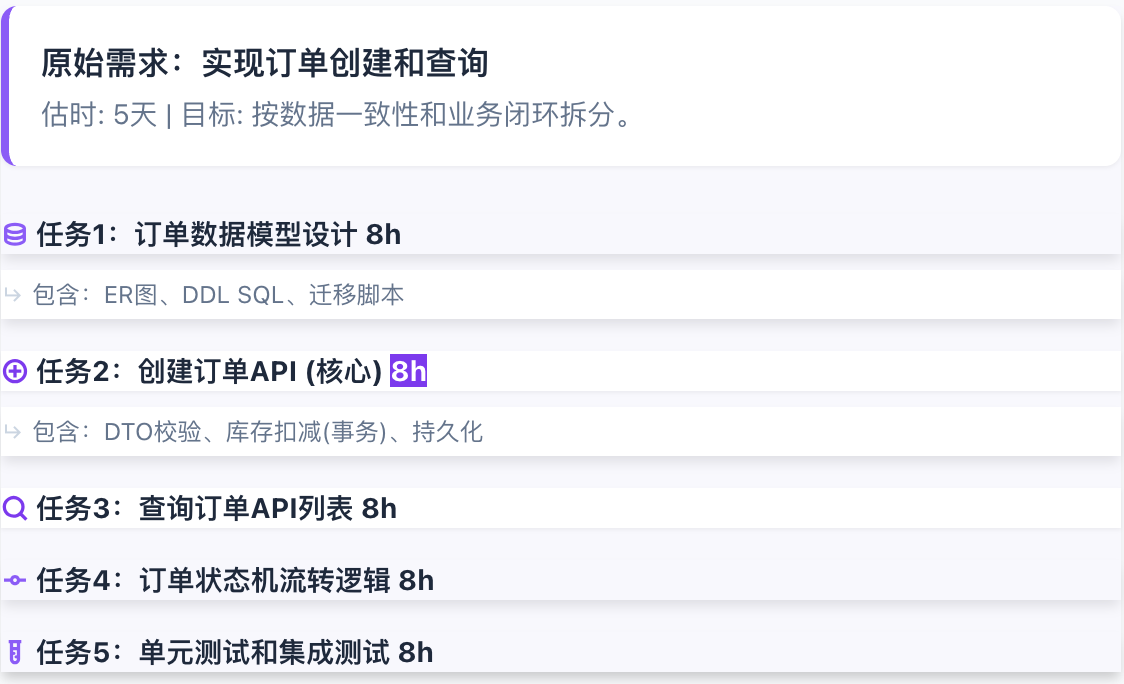
后端拆解示例 (API/逻辑边界)
将"订单服务"拆解为以API端点或业务逻辑为边界的独立任务:
后端任务的关键是事务边界清晰:T4(库存扣减)必须在一个任务内完成,不能拆成"扣减"和"回滚"两个任务,否则会破坏数据一致性。
特点:后端任务需要考虑事务完整性,不宜切分过细。
算法研究(1-3天)
拆解原则:采用Spike任务——一种专门用于技术调研或不确定性探索的时间盒任务,设置明确的时间上限强制产出结论,避免陷入"研究黑洞"
示例:优化推荐模型CTR

算法研究:Spike时间盒拆解
原始需求:提升推荐CTR 5%(时间不确定)
拆解后:
├── Spike 1:文献调研(1天)
│ └── 时间盒:不超过1天,产出调研报告
├── Spike 2:数据特征分析(1天)
│ └── 时间盒:产出特征分布报告
├── Spike 3:基准模型建立(1天)
│ └── 时间盒:产出baseline指标
├── 任务4:特征工程实验(2天)
│ └── 超参调优一轮闭环
└── 任务5:模型对比实验(2天)
└── A/B测试设计与执行
特点:通过"时间盒"防止陷入"研究黑洞",强制产出阶段性结论。
数据工程(1-3天)
拆解原则:以管道阶段为单位,必须考虑Schema变更的连锁影响
示例:构建用户行为数仓

数据工程:构建用户行为数仓
├── 任务1:源数据接入(1天)
├── 任务2:数据清洗规则(1天)
├── 任务3:维度表设计(1天)
├── 任务4:事实表设计(1天)
└── 任务5:聚合层开发(1天)
来源:QA在数据工程中的演进
四、职级与任务颗粒度的非线性映射
第三章按职能划分了拆解基准,但同一职能内部,初级工程师和高级工程师的最优粒度也截然不同。这不仅关乎能力差异,更涉及管理哲学的转变:对初级开发者,细粒度是保护网;对高级开发者,细粒度可能是枷锁。本章探讨如何根据职级调整任务颗粒度,在"保护"与"赋能"之间找到平衡。
4.1 初级开发者(Junior):0.5-1天
特点:
路径依赖强,容易偏离方向
需要高确定性的指令减少理解偏差
反馈周期越短,纠偏成本越低
管理策略:
任务必须严格控制在0.5-1天
明确的输入、输出和验收标准
每日检查点
4.2 中级开发者(Mid-level):2-5天
特点:
具备功能自治能力
能独立完成一个完整功能组件(Story)
管理重点在于交付确定性
管理策略:
可负责2-5天的功能组件
周级别的里程碑检查
给予一定的技术决策空间
4.3 高级开发者(Senior):周/月级别
特点:
战略自主,负责跨月、边界模糊的Epic或领域架构
需要深度思考和系统性设计
强行推行日级审计会侵蚀专业认同感
管理策略:
以里程碑而非日任务管理
关注方向对齐,而非过程细节
保护其心流状态,避免过度打断
警告:对高级开发者实施过细的任务拆解,可能导致:
专业认同感受损
系统性思考被打断
人才流失风险上升
4.4 协作模式对任务粒度的影响
前面三节讨论了"一个人独立工作时"的最优粒度,但现实中开发者很少完全孤立工作。当两个人结对编程,或者多人协作同一功能时,最优粒度又会发生变化——协作密度越高,越需要更细的粒度来保持同步。
结对编程:初级开发者的加速器
结对编程(Pair Programming) 看似投入了双倍人力,但实验数据显示其ROI往往为正:
为什么结对能提升效率?
实时代码评审:问题在产生时即被发现,而非等到PR阶段
认知负荷分担:一人专注编码逻辑,一人把控全局设计
知识均匀分布:避免"只有某人懂这块代码"的单点风险
最佳实践:结对编程特别适合初级开发者处理0.5-1天的任务——任务粒度小到当天可见成果,结对保证质量和学习效果。
代码评审:小PR的效率优势
小颗粒度PR(Pull Request) 不仅影响开发者体验,更直接影响评审效率:
150行临界点:研究显示,当PR超过150行代码时,评审者发现Bug的概率开始显著下降——不是因为Bug变少,而是因为认知超载导致评审质量下降。
代码评审质量与PR规模的关系:
下图展示了两条关键曲线的交叉:
蓝色曲线(评审质量/Bug发现率):在0-150行区间保持高位(约90%),150行后急剧下降,500行时降至约40%,1000行以上趋近于"形式化审批"
橙色曲线(评审时间):随PR规模线性增长,但超过500行后增长放缓——不是因为评审更高效,而是评审者开始"放水"
交叉点(约150行):此处评审ROI最高,投入时间适中且质量有保障
这就是所谓的"质量反转":PR越大,评审时间越长,但发现问题的能力反而越差。大PR带来的是"虚假安全感"——看似经过了评审,实际上关键问题可能被遗漏。
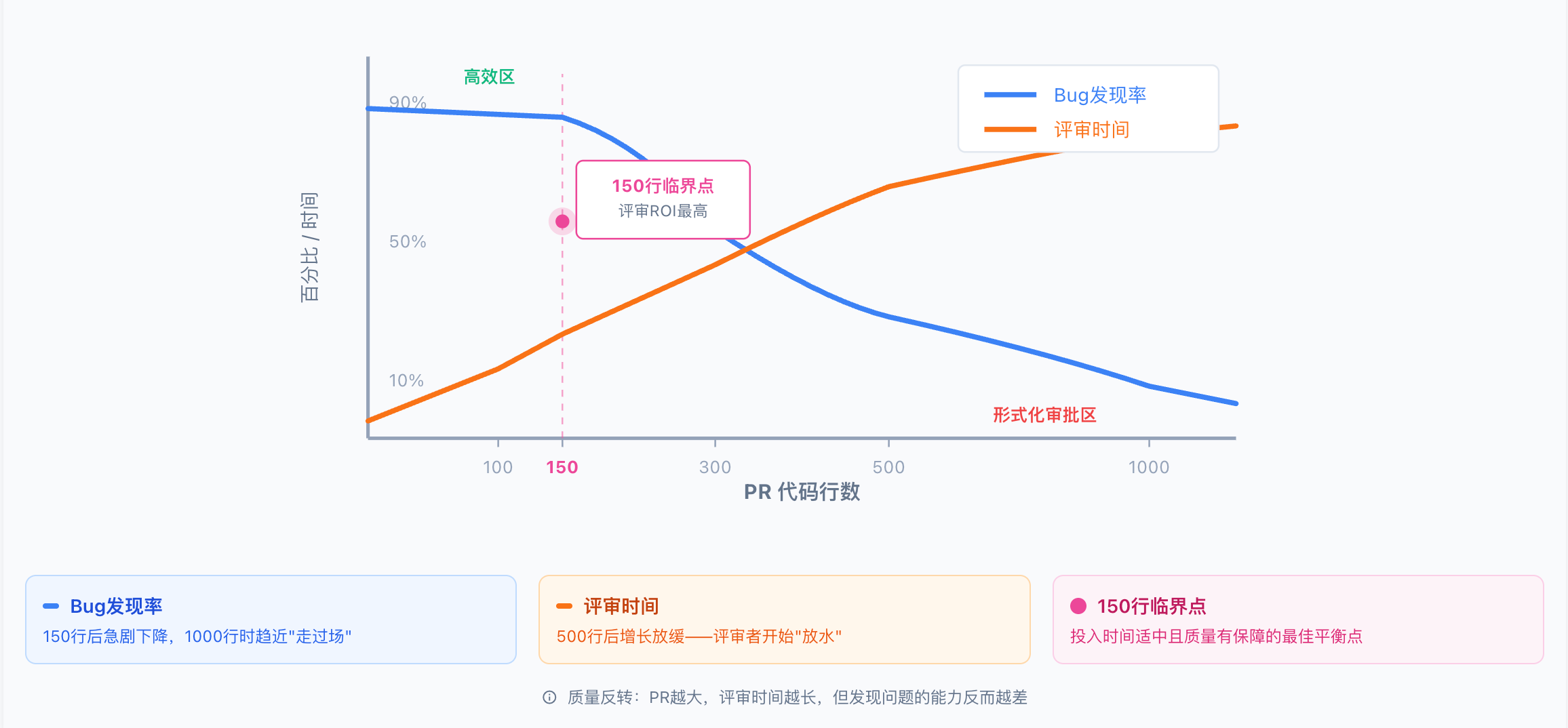
代码评审的质量反转
代码评审的隐藏价值:
知识均匀分布:降低代码贡献均衡度指标的偏差
质量门禁:65%的开发者表示,有自动化CI检查和代码评审流程后,工作压力显著减少
团队学习:评审是低成本的知识传递机制
来源:How Elite Teams Keep Their Coding Time Under Control - Axify
五、研发心理学:小胜、心流与任务边界
前四章从系统效率、大厂实践、职能差异、职级映射等角度分析了"怎么拆"的问题。第一章的认知负荷理论回答了"大脑能不能处理"——工作记忆的容量限制决定了任务不能太大。但"能做"不等于"想做"——本章要回答的是"开发者愿不愿做":
第一章视角:4-12小时任务匹配大脑处理能力(能力边界)
本章视角:4-12小时任务让人每天都有成就感(动力机制)
一个每天都能"划掉任务"的开发者,与一个连续三天"还在做那个需求"的开发者,心理状态天差地别。本章从心理学视角揭示:为什么"小胜"如此重要?为什么1天任务是"心流友好"的?这些问题的答案,将任务拆解从"管理技术"升华为"组织幸福感工程"。
5.1 进展原则:哈佛12,000份日记的发现
研究背景
哈佛商学院教授Teresa Amabile和心理学家Steven Kramer进行了一项大规模研究:
样本量:近12,000份工作日记
参与者:238名员工
跨度:7家不同公司
时长:数月的持续追踪
核心发现
"工作中最重要的驱动力是'进展感'——哪怕是微小的进展。"
研究结论:
进展感 > 金钱激励:日常的小进展比奖金更能激发动力
进展感 > 表扬认可:完成任务本身比被夸奖更让人满足
挫折的负面影响 > 进展的正面影响:一次挫折需要多次小胜才能弥补
对任务拆解的启示
开发场景对比:两种Sprint体验
将任务拆解为0.5-1天,能让开发者:
每天下班前感受到"完成(Done)"的成就感
持续获得多巴胺释放
问题早暴露,不会在Sprint最后一天爆雷
显著提升团队韧性和抗压能力
5.2 心流状态:挑战与技能的完美平衡
进展原则解释了"小胜"为什么重要——它提供了持续的正向反馈。但还有一个更深层的心理现象:当任务难度恰到好处时,开发者会进入一种被称为"心流"的最优体验状态,此时生产力和创造力都达到巅峰。这正是任务粒度设计需要考虑的另一个维度:**不仅要让任务"完得成",还要让任务"做得爽"**。
什么是心流?
心理学家Mihaly Csikszentmihalyi定义的 心流(Flow) 是一种:
"完全沉浸在活动中,忘记时间、失去自我意识、感受到深层目的感的最优体验状态。"
心流的8个核心特征
行动与意识合一:做事不需要刻意思考
高度专注:注意力完全集中在任务上
自我意识消失:忘记了"我"的存在
时间感扭曲:感觉时间飞逝或静止
控制感:感觉一切尽在掌握
内在奖励:活动本身就是奖励
挑战与技能平衡:不太难也不太简单
流畅的表现:毫不费力地做出高质量输出
触发心流的条件
心流发生在"挑战"与"技能"完美匹配的区间:
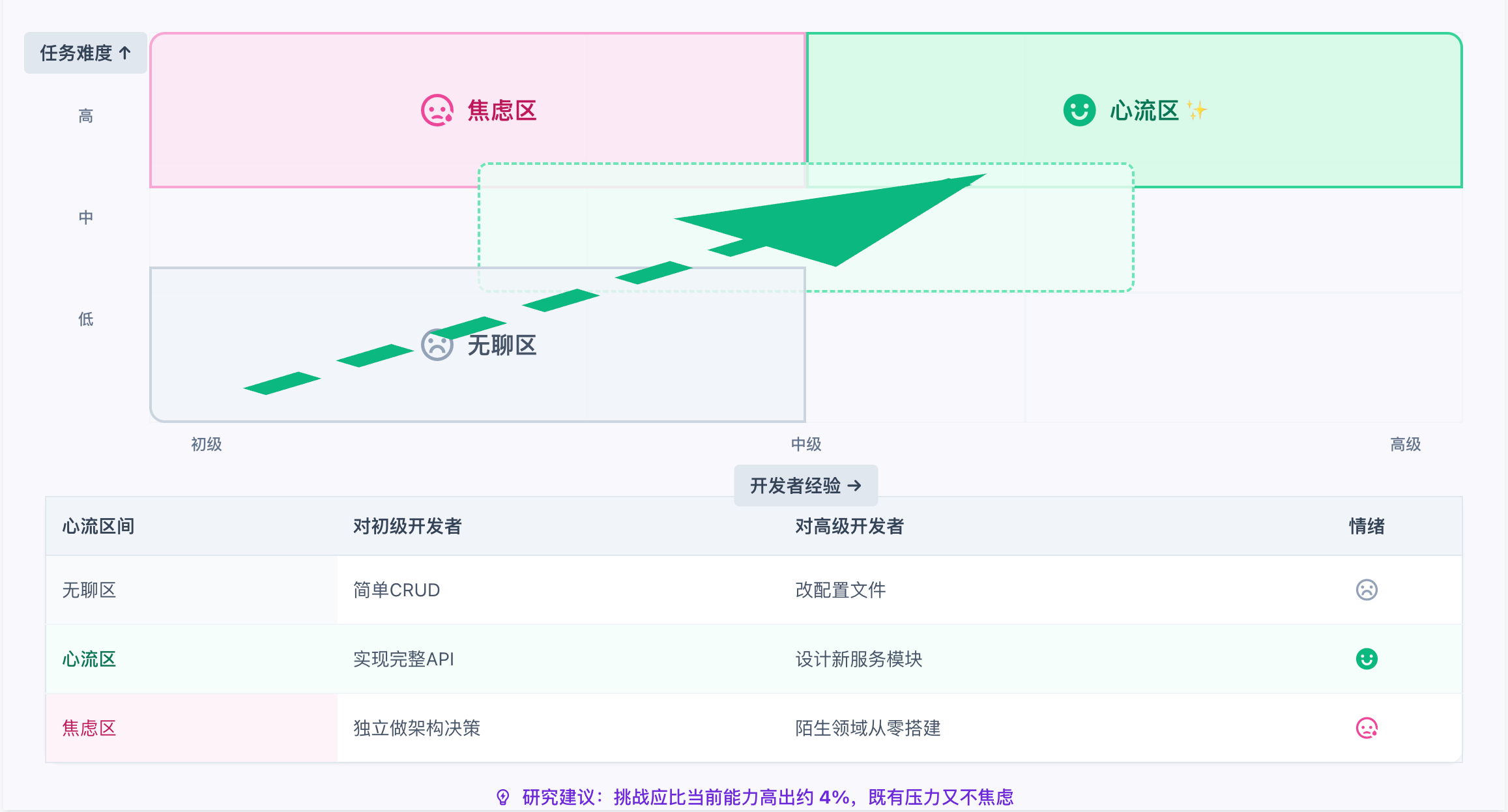
心流区间:挑战与技能的平衡
开发场景映射:
研究建议:挑战应比当前能力高出约 4% 左右,既有适度压力,又不会产生焦虑。
为什么1天任务是"心流友好"的?
以"实现商品收藏功能"为例:
足够的挑战:涉及API设计、数据库操作、前端交互,不是机械劳动
可达成的目标:今天开始,明天能看到收藏按钮真的能用了
清晰的反馈:CI通过、评审Approve、功能在测试环境可演示
沉浸的空间:上午进入状态后可以持续专注,不会被站会打断太多次
5.3 多巴胺循环:游戏化设计的借鉴
进展原则告诉我们"完成任务让人开心",心流理论告诉我们"任务难度要恰到好处"。但这些心理体验的底层机制是什么?答案藏在神经递质里。理解多巴胺循环,能帮助我们像游戏设计师一样,有意识地构建让开发者"上瘾"的正向反馈系统。
生理机制
当我们完成一个任务时,大脑会释放多巴胺——一种与愉悦和奖励相关的神经递质。

多巴胺正向循环
开发类比:CI/CD的即时反馈机制
为什么优秀的团队都重视CI/CD?因为它构建了一个完美的多巴胺循环:

研发多巴胺循环 (CI/CD的心理学机制)
反面案例:如果一个任务要做5天才能合并,开发者在这5天内几乎没有任何正向反馈,动力会持续衰减。
实践建议
让CI跑得快:超过10分钟的CI会让人失去等待的耐心
小PR快合并:评审者24小时内响应,让提交者尽快获得反馈
任务完成即刻更新看板:让"Done"的视觉反馈成为日常奖励
避免连续红灯:如果CI连续失败超过3次,暂停其他工作先修复
六、AI协作时代的规格驱动开发(SDD)
前五章讨论的任务拆解原则,核心假设是"人类执行任务"。但这个假设正在被颠覆——随着AI编程助手(如Cursor、Copilot、Claude)的普及,"谁来执行"的答案变了,"怎么拆解"的最优策略也随之改变。对人类开发者,4-12小时是黄金区间;但对AI智能体,30-90分钟才是甜蜜点。本章探讨这场"人机协作"革命对任务拆解范式的根本性影响。
AI对研发效能的冲击:
下图展示了AI介入前后研发各环节效能变化的对比:
下图直观展示了传统模式与AI增强模式下,研发各环节时间分布比例的显著变化。在传统模式中,编码实现占据了绝大部分时间,行政流程(等待评审、合规校验等)的占比相对较小;而当AI将编码执行时长极致压缩后,这些原本不起眼的行政流程反而成为了新的效能瓶颈。这揭示了一个关键洞察:AI时代的效能提升,不仅需要技术工具的升级,更需要组织管理方式的同步调整——简化审批流程、缩短评审等待、重新设计协作机制。
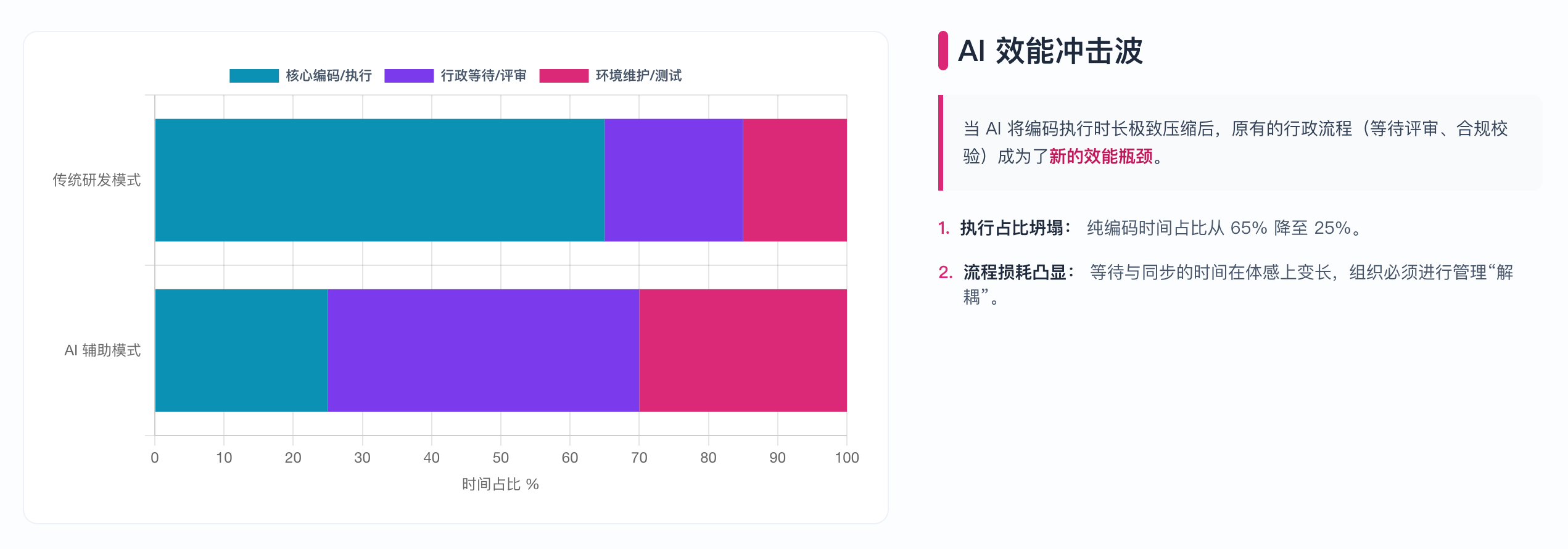
AI 效能冲击波:不同模式下的时间分布
6.1 30-90分钟的"超细粒度"时代
为什么AI需要更细的粒度?
在SDD(Spec-Driven Development)框架下:
人类职责从编码转向写规格说明书(Spec)
AI负责根据规格生成代码
AI擅长模式补全,不擅长"读心"
对于AI智能体,最理想的任务颗粒度是30-90分钟的生成时长。超过此限度:
AI"幻觉"概率显著增加
逻辑断层和上下文遗忘频发
生成的代码需要大量人工修正
人类 vs AI 粒度对比
6.2 SDD四阶段工作流详解
GitHub官方推出的Spec-Driven Development框架包含四个阶段:
阶段1:Specify(规格定义)
目标:将模糊想法转化为详细规格说明
输入:"我想要什么"的高层描述
输出:AI生成的详细规格,包含:
用户旅程和交互流程
要解决的问题
成功标准
预期结果
人类职责:验证规格是否准确捕捉了真实意图
关键原则:
"Focus on user experience, not technical implementation." (关注用户体验,而非技术实现。)
阶段2:Plan(方案设计)
目标:生成技术架构方案
输入:
技术栈偏好
架构约束
公司规范
合规要求
输出:AI生成的技术方案,包含:
系统架构图
数据流设计
部署策略
技术选型依据
最佳实践:
提前指定技术标准
包含遗留系统集成需求
定义性能目标
可以请求多个方案变体进行比较
阶段3:Tasks(任务拆解)
目标:将方案切分为AI可执行的微任务
输出:小型、可审核的任务块,每个任务:
可独立实现
可独立测试
具体明确
任务粒度的正反案例:
阶段4:Implement(自动化执行)
执行方式:AI按任务逐个或并行生成代码
人类职责:
审核聚焦于具体问题的变更
而不是"千行代码的海量dump"
每个PR应只对应一个微任务
优势:由于前三个阶段已经明确了"做什么、怎么做、何时做",AI生成的代码质量显著提升。
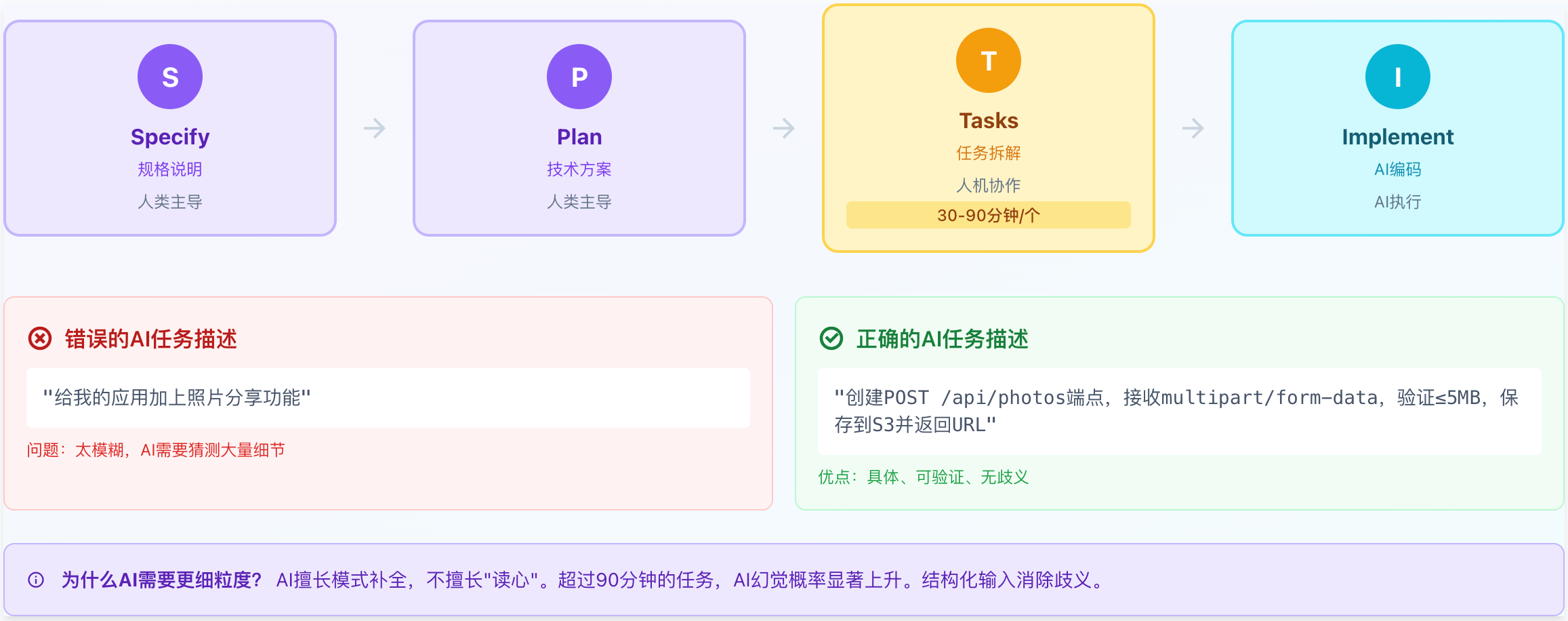
AI协作:Spec-Driven Development 工作流
6.3 人机协作新范式
角色重新分工
规格即"活文档"
在SDD中,规格不是一次性产出,而是随项目演进的活文档:
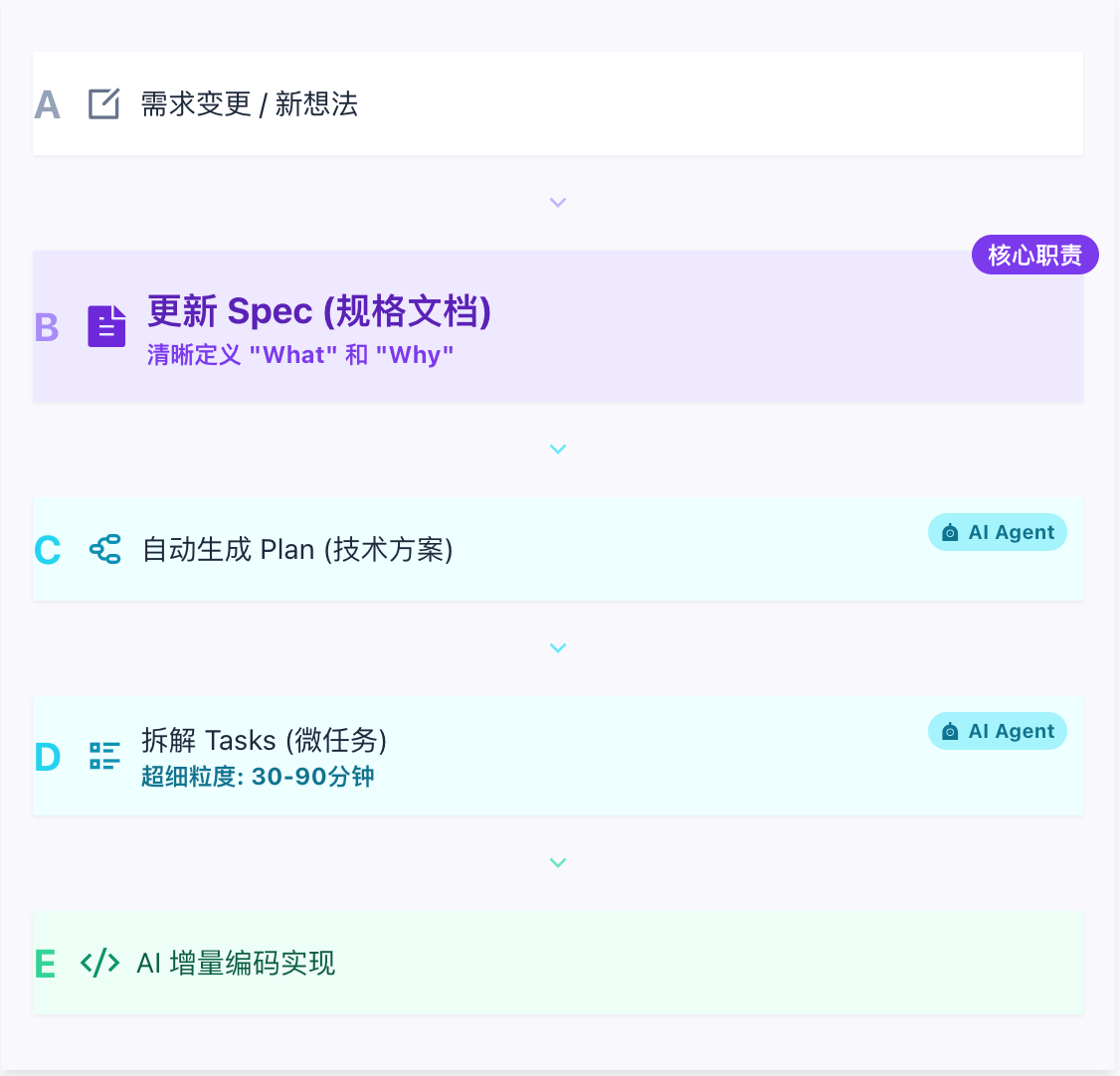
规格驱动开发 (SDD) 流程
优势:快速迭代而不需要昂贵的人工重写。
最佳适用场景
6.4 Agentic AI的三大核心能力
随着大语言模型(LLM)的成熟,AI正在从"被动工具"进化为"主动协作伙伴"。理解Agentic AI的核心能力,有助于更好地设计人机协作的任务拆解策略。
能力一:自主决策架构
AI能够自主理解业务需求,并在多个技术方案中进行权衡:
示例:当用户提出"处理大规模日志分析"时,AI可以自主分析:
Spark vs. DuckDB的优劣
内存容量约束
实时性要求
运维复杂度
并动态调整执行策略以保证结果最优。
能力二:自然语言交互
人机交互从复杂的代码编写转向自然语言对话:
降低了技术门槛
让开发者能力集中于业务逻辑的清晰表达
任务拆解从"程序化描述"变为"意图表达"
能力三:端到端智能流程
从需求理解、架构设计、环境配置到代码生成、性能测试,整个流程由AI统一协调,形成闭环的"Agentic Workflow"。
6.5 多智能体协作:Magentic-One编排者模型
微软开发的Magentic-One系统展示了AI Agent在任务分解方面的新范式。
编排者(Orchestrator)架构
下图展示了Magentic-One的多智能体协作架构:中央的Orchestrator(编排者)负责任务分解和调度,周围是专门化的执行Agent(如WebSurfer处理网页交互、Coder处理编码任务、FileSurfer处理文件操作等)。编排者通过"双账本"机制实时追踪任务进度和调整策略。
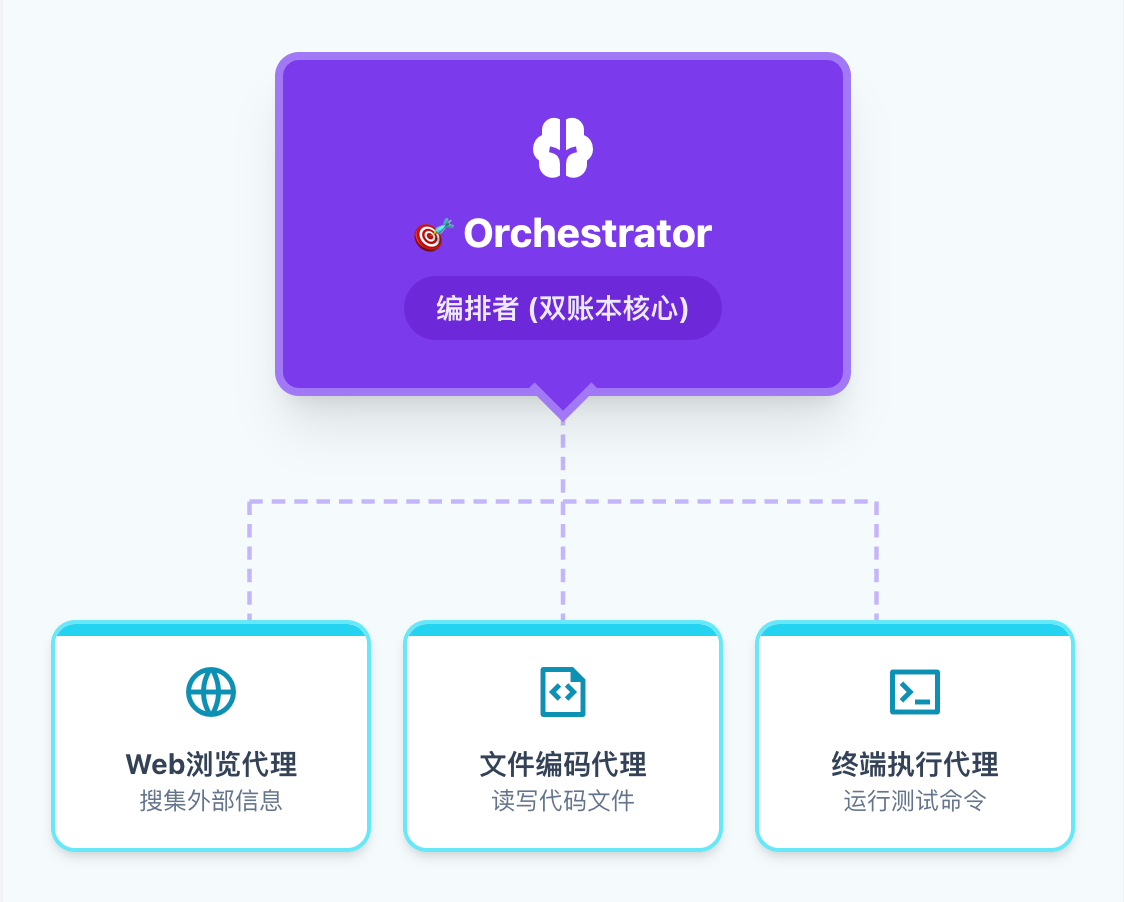
Magentic-One 多智能体编排
双账本机制
Magentic-One采用创新的"双账本"机制进行任务管理:
编排者会在进度账本中**实时"思考"**——如果发现某条路径走不通,会立即修改任务账本中的规划,而非盲目继续。
AI Agent在研发任务管理中的应用
来源:Magentic-One: A Generalist Multi-Agent System - Microsoft Research
6.6 人机协作的元认知要求
AI的引入对开发者的**"元认知"(Metacognition)** 能力提出了更高要求——即"对思考的思考"。
与AI共同构建任务意图
开发者需要学会:
清晰表达意图:将模糊的想法转化为AI能理解的结构化描述
验证AI输出:批判性审查AI生成的方案,而非盲目接受
迭代优化:通过多轮对话逐步细化任务定义
避免"盲目跟随AI"陷阱
研究表明,当开发者过度依赖AI时,可能出现:
批判性思维下降:不再质疑AI的建议
技能萎缩:长期不手写代码导致基础能力退化
责任模糊:出问题时不知道是自己的意图表达问题还是AI的理解问题
对策:AI系统应设计"认知摩擦"机制:
通过追问确认人类的真实意图
提供替代视角供人类参考
在关键决策点要求人类明确确认
最佳实践:在过度依赖与批判性审查之间找到平衡——AI负责"how"(怎么做),人类把控"what"和"why"(做什么、为什么)。
七、任务拆解实操指南
前六章建立了完整的理论框架:从系统效率到心理学,从大厂实践到AI协作。但"知道"和"做到"之间还有一道鸿沟——面对一个具体的需求,该如何一步步拆解成可执行的任务?本章提供一套实战工具箱:递归拆解的四问法、INVEST检查清单、以及一个完整的打卡功能拆解演练。读完本章,你将拥有一套可复制的操作流程。
7.1 递归拆解算法:Jacob的四问法
来自知名工程师Jacob Kaplan-Moss的任务拆解方法:
核心算法
function 拆解任务(任务列表):
for 每个任务 in 任务列表:
if 充分定义(任务):
继续下一个
else:
子任务列表 = 分解(任务)
拆解任务(子任务列表) // 递归
"充分定义"的四问检验
一个任务必须让你对以下**四个问题都回答"是"**:
只要有一个问题回答"否",就需要继续拆解。
停止拆解的时机
当任务满足以下条件时,停止拆解:
能在1天内完成
四问检验全部通过
可以立即开始工作
7.2 ETIP方法:原子任务执行
四问法帮助你判断"任务是否足够清晰",但在实际执行时,你可能还会遇到另一种情况:任务虽然清晰,但拿起来就是不想做——因为它看起来"还是有点复杂"。ETIP(Executable Task In Progress)方法是对四问法的补充,专门解决这个"启动阻力"问题,强调将任务分解至原子可执行形式——简单到"拿起来就能做"。
核心原则
将任务拆解至满足以下条件:
足够简单:降低对工作记忆的瞬时需求
不可再分:每个任务是一个完整的认知单元
可立即执行:无需额外信息收集
ETIP与认知负荷的关联
心理学洞察:这种细颗粒度的分解不仅提高了任务执行的确定性,还减少了因任务过于复杂而产生的心理压力和逃避行为。当任务足够简单时,大脑倾向于"直接开始"而非"继续拖延"。
7.3 任务分解的三种方法论
四问法和ETIP关注的是"什么时候停止拆解",但还没有回答"按什么思路去拆"。面对一个复杂需求,你可以自上而下逐层分解,也可以按用户旅程的步骤切分,还可以简单地列出线性步骤。不同的拆分思路适合不同场景——下面介绍三种常用方法论:
方法一:自上而下法(Top-Down)
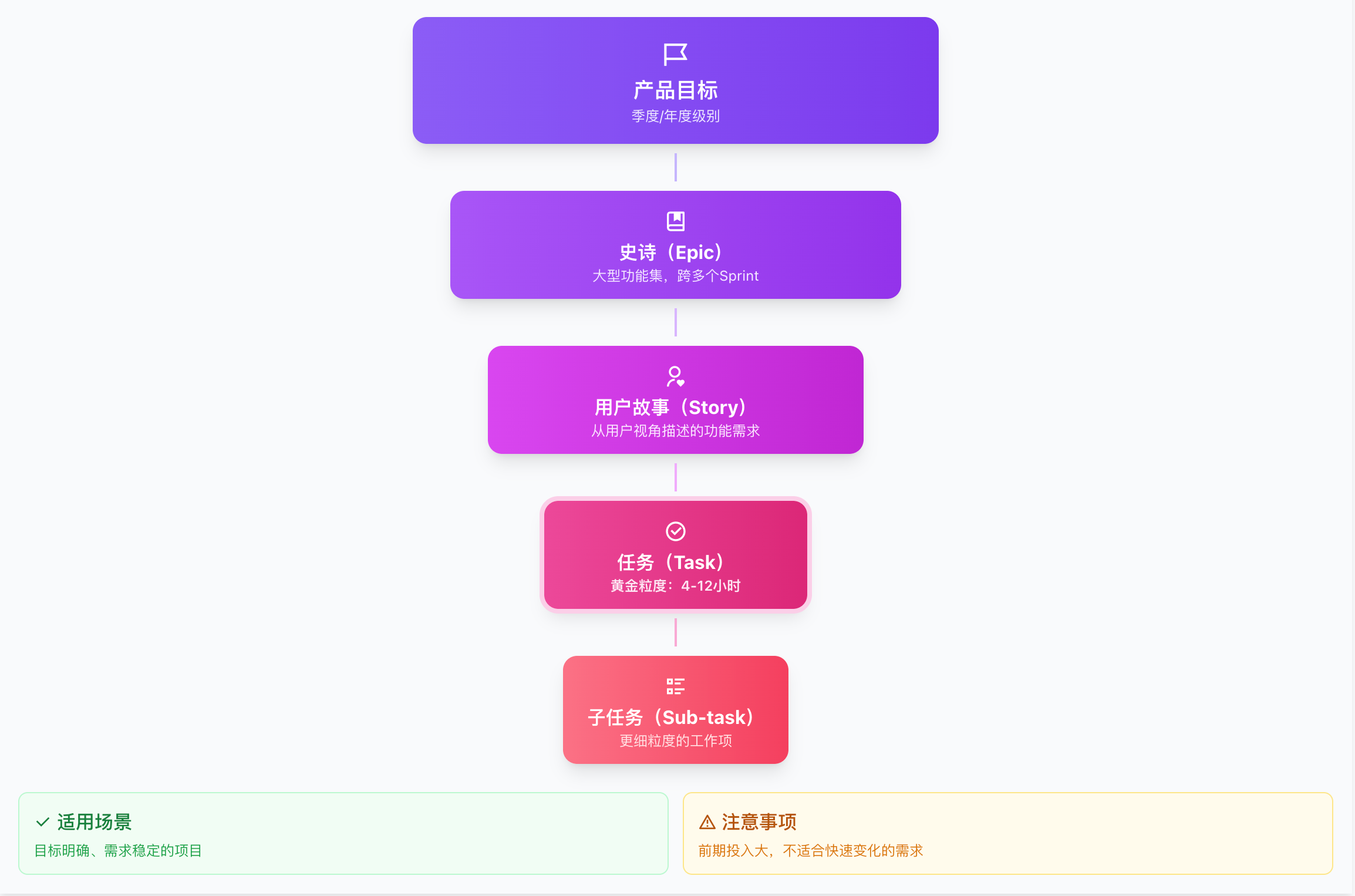
自上而下法(Top-Down)
从整体目标出发,逐步细化至底层任务。
产品目标
↓
史诗(Epic)
↓
用户故事(Story)
↓
任务(Task)
↓
子任务(Sub-task)
适用场景:目标明确、需求稳定的项目 优势:保证全局一致性,不遗漏需求 劣势:前期投入大,不适合快速变化的需求
方法二:层级任务分析(HTA, Hierarchical Task Analysis)

层级任务分析(HTA):用户购买流程
专注于工作流与依赖关系,将复杂操作拆解为子任务与操作步骤。
目标:用户完成购买
├── 1. 浏览商品
│ ├── 1.1 搜索商品
│ ├── 1.2 筛选分类
│ └── 1.3 查看详情
├── 2. 加入购物车
│ ├── 2.1 选择规格
│ └── 2.2 确认数量
└── 3. 完成支付
├── 3.1 确认订单
├── 3.2 选择支付方式
└── 3.3 完成支付
适用场景:流程驱动型功能、用户旅程优化 优势:清晰暴露依赖关系,便于识别瓶颈 劣势:可能过于关注"how"而忽略"why"
方法三:顺序分解(Sequential Decomposition)
将任务拆解为线性的步骤序列。
Step 1 → Step 2 → Step 3 → Step 4 → Done
适用场景:简单、线性的任务 优势:简单明了,易于跟踪进度 劣势:容易忽略并行可能性,可能拖慢整体进度
方法选择指南
7.4 任务层级结构详解
掌握了"如何拆解"的方法论后,还需要理解"拆成什么"——敏捷开发中的任务层级(Epic → Story → Task)并非随意命名,而是有严谨的结构定义。理解这套层级体系,能帮助你在正确的层次上应用正确的粒度。
目标(Goal)
│
├── 史诗(Epic):大型功能集,通常跨多个Sprint
│ │
│ ├── 用户故事(User Story):从用户视角描述的功能需求
│ │ │
│ │ ├── 任务(Task):开发者的具体工作单元
│ │ │ │
│ │ │ └── 子任务(Sub-task):更细粒度的工作项
│ │ │
│ │ └── 验收标准(Acceptance Criteria):完成的定义
│ │
│ └── 技术任务(Technical Task):非功能性工作
│
└── 里程碑(Milestone):关键检查点
各层级的典型粒度
层级过多的反模式
警告:层级不是越多越好。过多的层级会导致:
管理开销爆炸
任务追踪困难
开发者迷失在层级中
推荐:保持3层(Epic → Story → Task)是最佳实践。
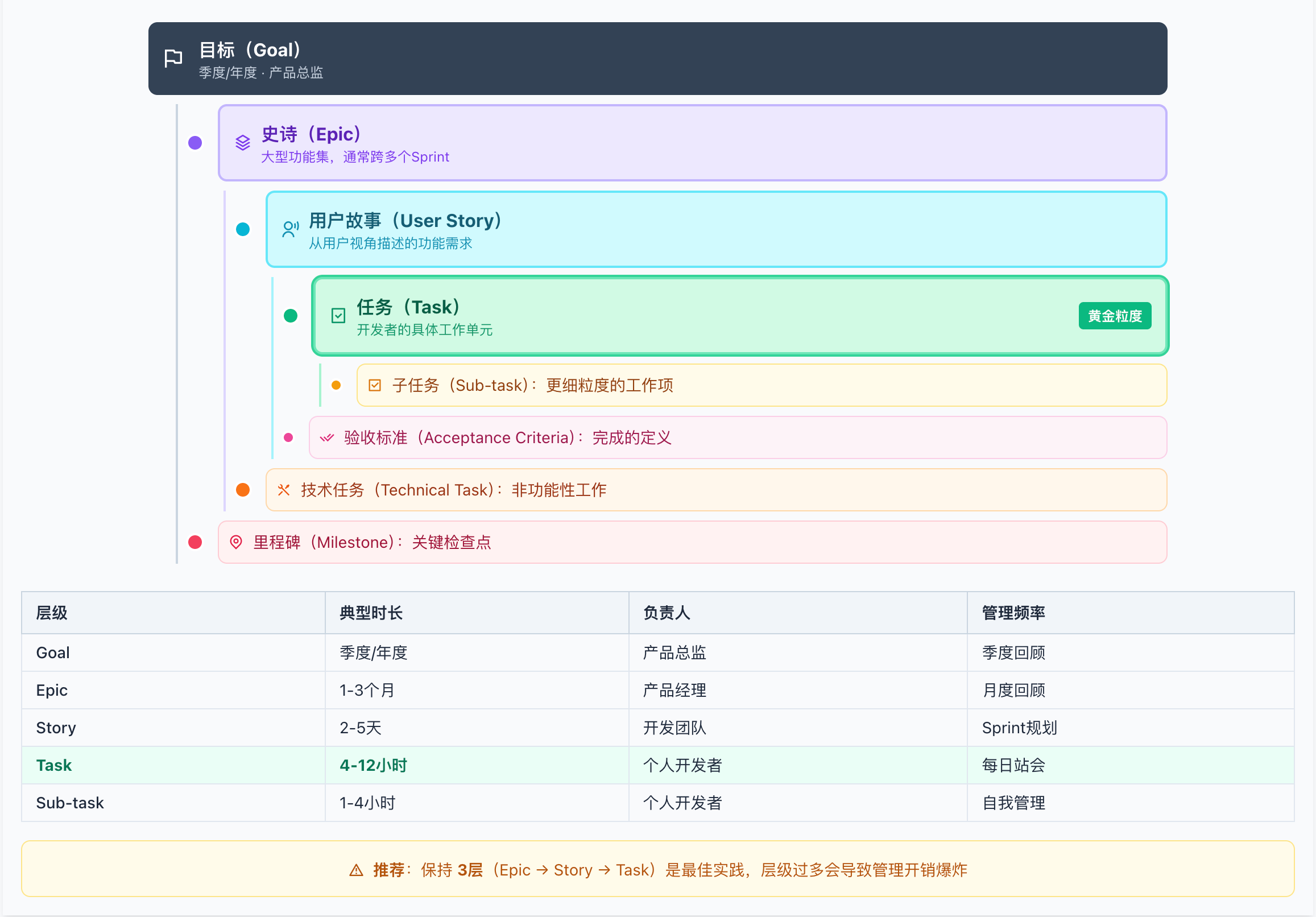
敏捷任务层级结构
来源:Task Decomposition in Agile Product Development - ProductGo
7.5 实战案例:打卡功能拆解演练
理论讲了很多,但最好的学习方式是看一个完整的例子。下面用一个真实的需求——"实现习惯打卡功能"——演示如何运用四问法进行递归拆解,从模糊的原始需求到可执行的任务清单。
原始需求:实现一个习惯打卡功能
第一轮:初步拆解
打卡功能
├── 数据建模
├── 日历视图
├── 交互功能
├── 连续天数计算
└── 冻结功能
检验:"数据建模"是否充分定义?
❌ 不清楚具体要建什么表
❌ 不知道字段有哪些
→ 需要继续拆解
第二轮:深入拆解
打卡功能
├── 数据建模(继续拆解)
│ ├── 习惯表设计(4h)
│ │ └── 字段:id, name, icon, color, created_at
│ ├── 打卡记录表设计(4h)
│ │ └── 字段:id, habit_id, date, status
│ ├── 数据库迁移脚本(2h)
│ └── 基础CRUD API(4h)
│
├── 日历视图(继续拆解)
│ ├── 月视图组件(4h)
│ ├── 日期单元格组件(4h)
│ ├── 打卡状态样式(2h)
│ ├── 月份切换功能(2h)
│ └── 今日高亮(1h)
│
├── 交互功能
│ ├── 点击日期打卡/取消(4h)
│ └── 打卡成功动画(2h)
│
├── 连续天数计算
│ └── 暂不实现,硬编码模拟数据(标记:后续任务)
│
└── 冻结功能
└── 暂不实现(标记:后续任务)
第三轮:最终确认
对每个叶子任务进行四问检验:
最终产出:12个可执行任务,每个4小时以内。

递归拆解演练:打卡功能
7.6 INVEST原则检查清单
拆解完成后,如何验证拆解质量?最后提供一份实用的INVEST清单——在Sprint Planning时,用它逐项检验每个User Story,确保不会遗漏关键标准(关于INVEST原则的详细解释,参见2.1 阿里巴巴:2-1-1愿景与INVEST原则):
## INVEST检查清单
### Independent(独立)
- [ ] 这个Story能否独立开发,不依赖其他未完成Story?
- [ ] 这个Story能否独立测试?
- [ ] 这个Story能否独立部署?
### Negotiable(可协商)
- [ ] 这是一个对话起点,而非固定合同?
- [ ] 实现细节是否有讨论空间?
### Valuable(有价值)
- [ ] 能用一句话说明这对用户的价值吗?
- [ ] 完成后用户能感知到变化吗?
### Estimable(可估算)
- [ ] 团队能否给出置信度>80%的估时?
- [ ] 如果不能,是否需要先做Spike调研?
### Small(小)
- [ ] 能否在一个Sprint内完成?
- [ ] 估时是否在1-5天之间?
- [ ] 如果>5天,是否需要拆分?
### Testable(可测试)
- [ ] 验收标准是否明确?
- [ ] QA能否据此编写测试用例?
八、常见误区与反模式
掌握了正确的方法,还需要识别错误的陷阱。在实践中,很多团队即使了解任务拆解的理论,仍然会掉入一些"看似合理实则有害"的模式。本章总结五个最常见的误区:从"为拆而拆"的形式主义,到"水平切片"的技术陷阱,再到"古德哈特定律"揭示的指标博弈。了解这些反模式,能帮助你在实践中少走弯路。
8.1 为拆而拆

误区一:为拆而拆
症状:
拆出的任务无法独立运行或测试
任务之间强耦合,必须同时完成才有意义
合并时发现大量冲突
案例:
❌ 错误拆分:
├── 任务1:写函数声明
├── 任务2:写函数实现
└── 任务3:写函数测试
问题:任务1-2无法独立验证,合并时必然冲突
正确做法:
✓ 正确拆分:
├── 任务1:实现功能A(含声明+实现+测试)
├── 任务2:实现功能B(含声明+实现+测试)
└── 任务3:实现功能C(含声明+实现+测试)
原则:每个任务应该是垂直切片(完整功能),而非水平切片(技术层)。
8.2 水平拆分陷阱

误区二:水平拆分陷阱
症状:
按技术层而非功能拆分
前端、后端、数据库分别作为独立任务
集成时才发现接口不匹配
案例对比:
以"实现用户收藏商品功能"为例,对比两种拆分方式:
❌ 水平拆分(按技术层):
├── 任务1:数据库表设计(后端) → 完成后无法演示
├── 任务2:收藏API开发(后端) → 完成后无法演示
├── 任务3:收藏按钮UI(前端) → 完成后无法演示
└── 任务4:前后端联调(全栈) → 集成时发现接口不匹配!
问题:前3个任务都无法独立验收,直到任务4才发现设计问题。
✓ 垂直拆分(按功能切片):
├── 任务1:收藏按钮点击(含API+UI+DB) → 点击后商品进入收藏列表 ✓
├── 任务2:取消收藏(含API+UI) → 点击后商品从列表移除 ✓
├── 任务3:收藏列表页(含API+UI) → 能看到所有已收藏商品 ✓
└── 任务4:收藏状态同步(含缓存逻辑) → 多端状态一致 ✓
优势:每个任务完成后都能端到端演示,问题即时暴露。
8.3 估时乐观偏差
症状:
总是低估任务所需时间
"这很简单,半天就搞定"最后花了三天
Sprint结束时大量任务未完成
原因:
规划谬误(Planning Fallacy):人类天生倾向于低估完成任务的时间
只考虑"纯开发时间",忽略了会议、审核、修改等
没有考虑意外情况的缓冲
对策:
8.4 忽略依赖关系
症状:
并行分配了有依赖的任务
A任务等B任务,B任务等A任务
关键路径上堆积了太多任务
对策:
拆解时显式标注依赖
绘制任务依赖图
识别关键路径,优先完成
对有依赖的任务,考虑Mock或Stub解耦
8.5 古德哈特定律
什么是古德哈特定律?
英国经济学家Charles Goodhart提出了一个著名的警告:
"When a measure becomes a target, it ceases to be a good measure." (当一个度量指标变成目标时,它就不再是一个好指标了。)
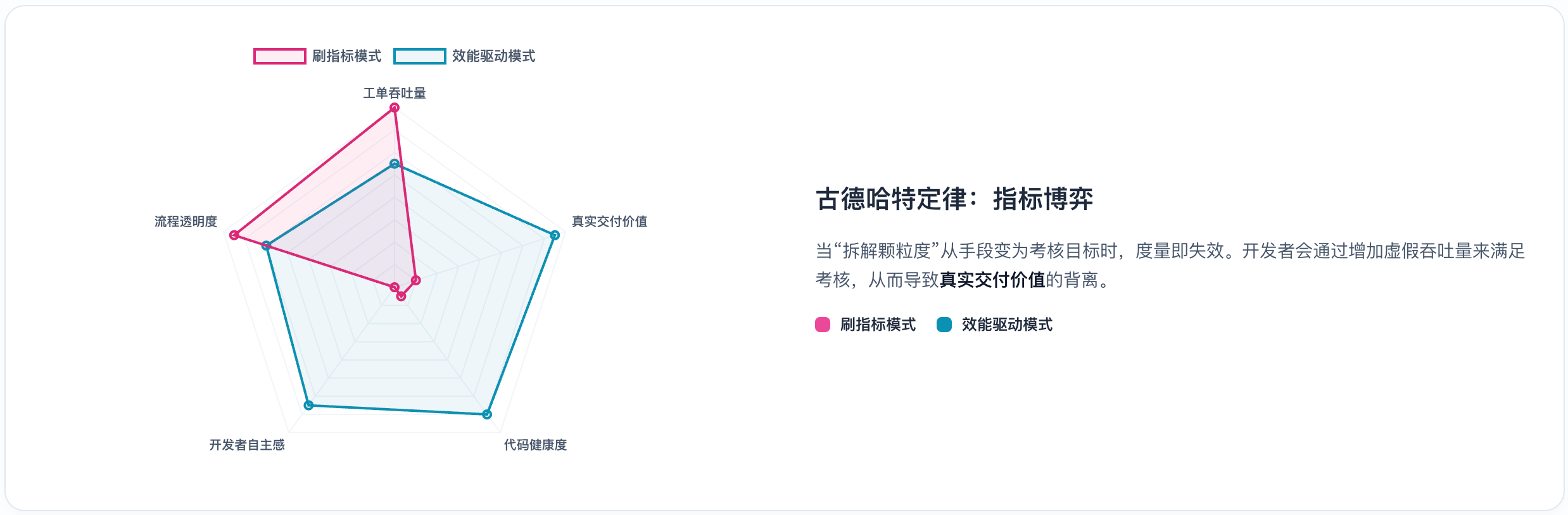
古德哈特定律:指标博弈
在软件研发中,由于工作内容的不可见性和高度复杂性,度量指标极易引发博弈行为(Gaming)。一旦某个指标与绩效挂钩,开发者就会找到"优化指标"而非"优化效能"的方法。
任务拆解中的典型博弈行为
开发场景:任务完成数的博弈
场景:团队KPI包含"每Sprint完成任务数"

古德哈特定律:任务拆解博弈
博弈前(正常拆解):
├── 用户登录功能 (1天)
├── 用户注册功能 (1天)
└── 密码重置功能 (1天)
完成任务数:3个
博弈后(指标优化):
├── 登录-表单UI (2h)
├── 登录-验证逻辑 (2h)
├── 登录-API对接 (2h)
├── 登录-错误处理 (2h)
├── 注册-表单UI (2h)
├── 注册-验证逻辑 (2h)
... (以此类推)
完成任务数:12个 ✓ 指标翻4倍!
实际后果:
- 站会时间翻倍(汇报12个任务 vs 3个)
- 看板管理成本上升
- 每个"任务"都无法独立交付价值
- 团队精力消耗在"拆任务"而非"做事情"
科学应对:指标对冲策略
为了对抗博弈心理,科学的度量体系应采用 "指标对冲(Counter-metrics)" 逻辑——每个主指标都配一个"照妖镜":
任务拆解的"防博弈"原则
不要单独考核任务完成数
正确做法:考核"交付的用户价值"或"可独立上线的功能数"
定义"有效任务"的标准
必须可独立测试
必须可独立演示
必须有明确的验收标准
关注流动效率而非数量
与其数"完成了多少任务",不如看"从开始到交付用了多久"
定期审视拆解质量
如果发现团队平均任务粒度持续下降,可能是博弈信号
来源:
8.6 法则的边界与例外
本报告反复强调"4-12小时"是黄金区间,但任何法则都有适用边界。盲目套用而不考虑上下文,本身就是一种反模式。以下场景需要差异化处理:
场景一:探索性研究与技术调研
特征:结果不确定,无法预先定义"完成"标准
正确做法:
设置时间盒(Timebox) 而非任务边界:例如"用3天时间调研,无论结论如何都输出报告"
允许更大粒度:探索性任务可以是3-5天
定义输出物而非结果:要求产出"调研报告"而非"可行方案"
场景二:创意设计与架构设计
特征:需要完整的思考周期,打断会破坏创意流
正确做法:
保护完整的思考时间块:给架构师安排1-2天不被打断的设计时间
延迟拆解:设计阶段用"设计输出物"作为里程碑,而非按小时拆分
分离"思考"与"文档化":先允许发散思考,再将结果结构化
场景三:深度重构与技术债务清理
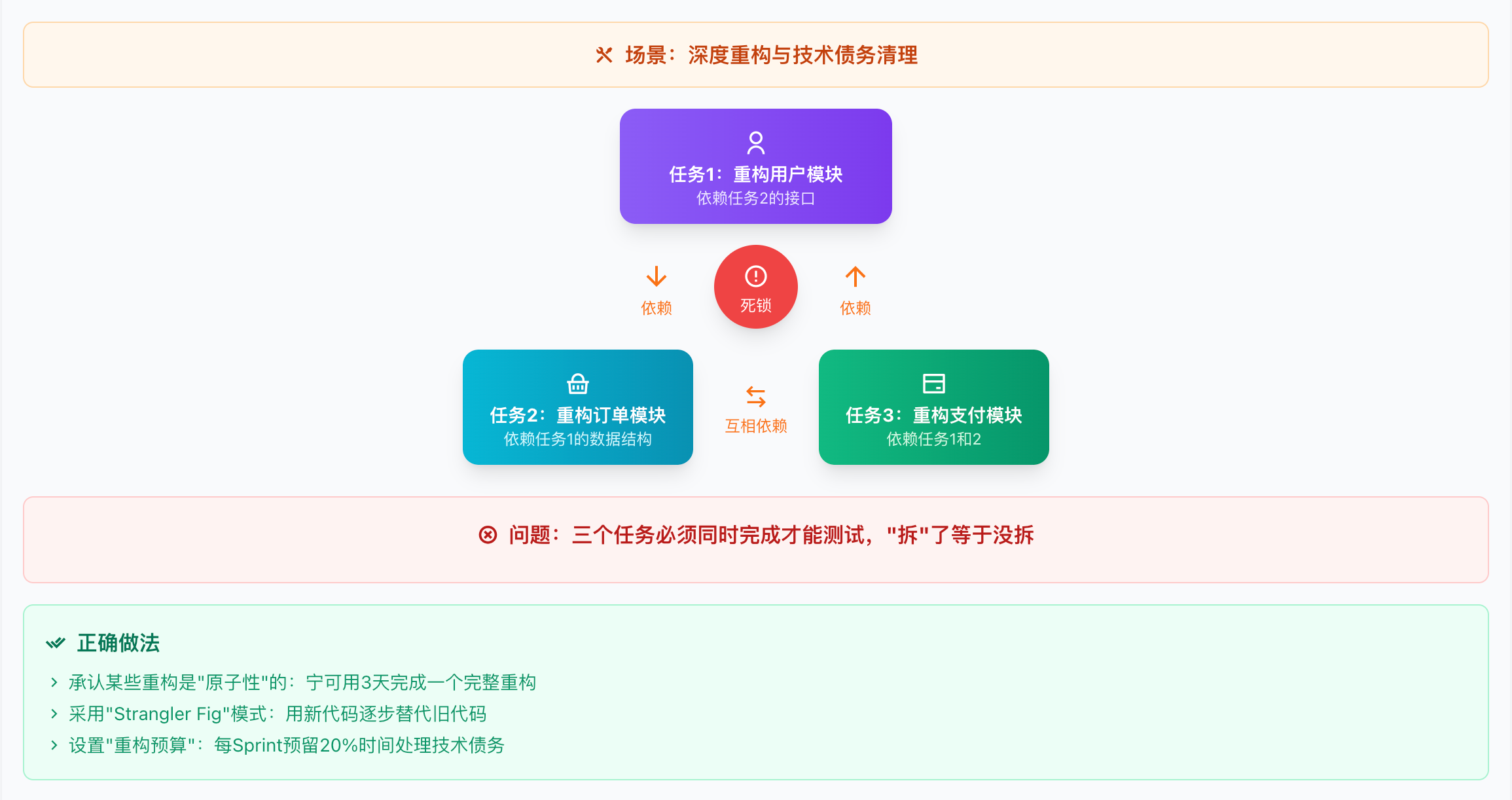
反模式:循环依赖
特征:改动范围大,相互依赖,难以拆成独立单元
❌ 强行拆解的后果:
├── 任务1:重构用户模块(依赖任务2的接口)
├── 任务2:重构订单模块(依赖任务1的数据结构)
└── 任务3:重构支付模块(依赖任务1和2)
问题:三个任务必须同时完成才能测试,"拆"了等于没拆
正确做法:
承认某些重构是"原子性"的:宁可用3天完成一个完整重构,不要拆成6个互相依赖的1天任务
采用"Strangler Fig"模式:不改旧代码,用新代码逐步替代
设置"重构预算":每个Sprint预留20%时间处理技术债务,不与功能任务混用
场景四:跨团队协作与外部依赖
特征:进度受他人控制,自身效率再高也可能被阻塞
正确做法:
显式区分"工作时间"与"等待时间":一个任务可能只需4小时开发,但总周期是3天(因为要等外部评审)
并行化:在等待A团队反馈时,先开始B任务
设置"超时升级"机制:如果等待超过24小时,自动升级为阻塞问题
场景五:紧急生产事故
特征:时间紧迫,无法按流程拆解
正确做法:
先止血,后复盘:紧急修复时不要求遵循粒度规范
事后补全:修复完成后,补充任务记录和根因分析
设置事故时间预算:如果紧急修复频繁发生,说明系统稳定性有问题,应优先解决根因
场景六:个人深度工作偏好
特征:部分高级开发者在长时间不被打扰时效率更高
"有些人是马拉松选手,不是短跑运动员。强迫他们每4小时交付一次,等于让马拉松选手每100米停下来报告一次。"
正确做法:
因人而异:对于有track record的高级开发者,可以放宽到2-3天
信任但验证:给予自主权,但仍要求在关键节点同步进度
结果导向:只要最终交付质量高、准时,粒度可以灵活
文化差异考量
不同文化背景对"每日闭环"的接受度不同:
总结:法则的正确使用姿势
核心原则:4-12小时法则是默认值,不是枷锁。 理解其背后的原理(认知负荷、反馈周期、风险控制),才能知道何时该遵守、何时该灵活。

边界与例外:何时不适用4-12小时法则
九、一页纸决策表
前八章内容丰富,但在日常工作中,你不可能每次都翻阅全文。本章将核心结论浓缩为几张速查表——无论你是在Sprint Planning会上需要快速判断,还是在Code Review时想确认粒度是否合理,都可以直接查阅这里。把这一页打印出来贴在显示器旁边,让最佳实践触手可及。
9.1 按执行者职级
9.2 按任务性质
9.3 按协作模式
9.4 按项目阶段
十、研发效能度量体系
随着研发效能领域的成熟,度量方式已从单一的生产力指标转向系统化的评价框架。科学的度量体系是任务粒度优化的基础——没有度量,就无法判断粒度调整是否带来了真正的改善。
10.1 主流效能度量框架对比
当前业界公认的三大度量框架各有侧重:
DORA四大指标详解
DORA(DevOps Research and Assessment) 是Google Cloud团队建立的行业基准:
SPACE框架:人文视角的引入
SPACE框架强调效能不等于产出,还需关注开发者的健康度:
Satisfaction(满意度):开发者对工作的满意程度
Performance(表现):代码质量、任务完成率
Activity(活跃度):提交频率、评审参与度
Communication(沟通):协作效率、知识共享
Efficiency(效率):流程顺畅度、工具有效性
关键洞察:过度追求Activity指标(如提交次数)可能损害Satisfaction和真正的Performance。
10.2 麦肯锡的内环/外环模型
麦肯锡在DORA与SPACE基础上,提出了"以机会为中心"的度量视角,重点关注开发者时间分配。
内环 vs 外环活动
麦肯锡将开发者的日常活动划分为两个同心圆:
内环活动(高价值):
编写代码、设计架构、调试问题
技术学习、代码评审(学习视角)
与用户/产品的深度沟通
外环活动(低价值但必要):
等待CI/CD流水线
等待代码评审
参加状态同步会议
处理环境问题、权限申请
填写各类表单和报告
下图以同心圆形式展示这一模型:中心(内环)代表高价值创造活动,外围(外环)代表支持性但低价值的活动。理想状态是"内环尽可能大,外环尽可能薄"。

麦肯锡内环/外环模型 (开发者时间分配)
顶级公司的标准:让开发者在内环活动上花费70%以上的时间,通过自动化工具最大限度减少外环活动的摩擦。
任务粒度对内外环的影响
10.3 效能度量的"五项精进"
了解DORA、SPACE、麦肯锡这些框架只是第一步。真正的挑战在于:如何在自己的团队中落地实施?以下五项精进措施,从数据采集到运营体系,构建了一套完整的度量闭环:
精进一:数据自动采集
原则:通过MQ、API等方式从研发工具链中静默提取数据,避免人工填报造成的误差。
实践:
Git提交自动关联Jira任务
CI/CD流水线自动记录构建时长
IDE插件静默采集编码时间
精进二:指标定义一致性
原则:确立"北极星指标",在全公司范围内统一统计口径,消除沟通歧义。
反面案例:
A团队的"完成"是合并到develop
B团队的"完成"是上线到生产
导致交付周期数据无法对比
精进三:效能度量模型构建

效能度量:价值流状态流转
原则:将流时间、流速率、流负载等指标整合,讲述完整的交付价值流故事。
需求提出 → 开发中 → 评审中 → 测试中 → 待发布 → 已上线
│ │ │ │ │
└─────────┴─────────┴────────┴─────────┘
流动时间
精进四:度量产品建设
原则:将原始数据转化为知识,支持下钻分析与根因诊断,输出自动化效能报告。
产品能力:
团队效能仪表盘
个人贡献趋势图
瓶颈自动识别
改进建议生成
精进五:效能运营体系
原则:避免指标KPI化导致的虚假繁荣,坚持"度量是学习与持续改进的工具"。
警告:当度量指标与绩效强挂钩时,古德哈特定律必然生效——人们会优化指标本身,而非指标所代表的真正目标。
10.4 DevData 2025基准数据
有了框架和落地方法,你可能还会问:我的团队表现到底算好还是差?需要有一个参照系。下面是《DevData 2025研发效能基准报告》提供的行业数据——用它来校准你的效能目标:
关键发现:随着AI在研发全流程的渗透,代码提交的颗粒度变得更加精细——这反映了SDD等新范式对任务拆解的影响。
来源:
十一、结论与最终建议
走到这里,让我们回顾这趟探索之旅:我们从METG和Amdahl定律出发,理解了任务粒度背后的系统工程原理(第一章);考察了从阿里巴巴到Google的全球大厂实践,看到了"1天"这个神奇数字如何反复出现(第二章);分析了前端、后端、算法、QA等不同职能的差异化需求(第三章);探讨了初级与高级开发者之间的非线性映射关系(第四章);揭示了进展原则和心流状态对开发者心理的深刻影响(第五章);见证了AI协作时代对粒度要求的颠覆性变革(第六章);学习了四问法等实操工具(第七章);识别了常见的拆解陷阱(第八章);并构建了一页纸速查决策表(第九章)和度量体系(第十章)。
现在,是时候把这一切浓缩为可执行的行动指南了。
11.1 三条黄金准则
人类开发者:以 1天(0.5-1.5天) 为平衡效率与风险的"黄金分割点"
AI协作:以 30-90分钟 为驱动智能体的原子单位
分层配比:2-5天的 User Story 对应 0.5-1.5天的 Sub-Task,实现每日反馈回路
11.2 决策底线
不要为拆而拆。如果拆解后的任务无法独立运行或测试,说明拆解过度,应合并以保持逻辑完整性。
11.3 最终结论
选择"1天"作为最小粒度,本质上是选择了一种 "主动防御" 的管理策略:
利用物理时间的紧迫感强制团队进行深度的前期思考
通过高频的闭环反馈消除不确定性
利用"小胜"的心理效应维持团队的高昂士气
在软件开发的马拉松中,保持高频、小步的节奏感,远比一周一大跳的爆发力更能确保最终交付的确定性。
动态颗粒度决策流程:
下图展示了任务粒度决策的完整流程,帮助你在实际工作中快速判断:
开始:收到一个任务
│
▼
[1] 执行者是谁?
├─ 人类开发者 → 进入判断2
└─ AI智能体 → 目标粒度:30-90分钟
│
▼
[2] 执行者经验如何?
├─ 初级(<2年)→ 目标粒度:0.5-1天
├─ 中级(2-5年)→ 目标粒度:1-3天
└─ 高级(>5年)→ 目标粒度:3-5天(可信任)
│
▼
[3] 任务性质是什么?
├─ 功能开发 → 使用上述粒度
├─ Bug修复 → 压缩至2-4小时
├─ 技术调研 → 设时间盒(1-3天)
└─ 紧急修复 → 不限粒度,先解决问题
│
▼
[4] 最终检验:四问法
├─ 能独立测试吗?
├─ 能独立演示吗?
├─ 估时置信度>80%吗?
└─ 能当天/次日完成吗?
│
▼
全部Yes → 粒度合适,开始执行
任一No → 继续拆分或调整
这个流程图将本报告的核心结论浓缩为可执行的决策路径,建议打印出来作为Sprint Planning的辅助工具。
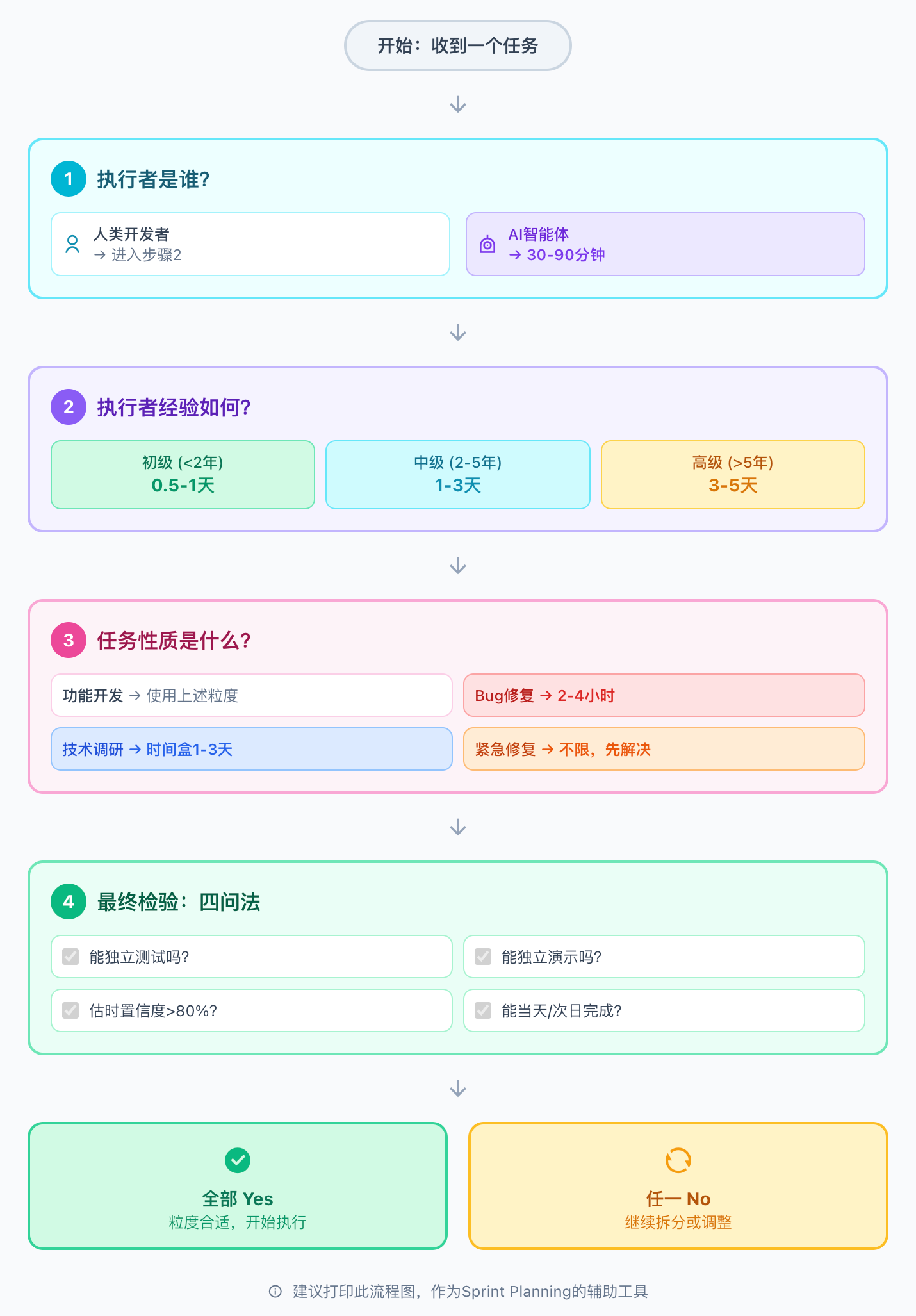
动态颗粒度决策流程
动态颗粒度决策
十二、落地工具与模板
理论再完美,最终要落地到工具和流程中。本章提供具体的工具配置建议、可复用的模板,以及在现有团队渐进式推行任务粒度优化的路径。
12.1 工具推荐
任务管理工具对比
根据团队规模、技术栈和工作流偏好,选择合适的任务管理工具至关重要。下表对比了主流工具在任务粒度支持方面的特点:

任务管理工具对比
Jira最佳配置建议
# Jira项目配置示例
Issue Types:
Epic:
description: "大功能模块,对应一个业务目标"
typical_duration: "2-4周"
Story:
description: "用户故事,遵循INVEST原则"
typical_duration: "2-5天"
required_fields:
- acceptance_criteria
- story_points
Sub-task:
description: "原子任务,可当日完成"
typical_duration: "4-12小时"
required_fields:
- original_estimate
- assignee
Workflows:
Sub-task:
- To Do → In Progress(开始工作时)
- In Progress → In Review(提交PR时)
- In Review → Done(PR合并时)
Automation Rules:
- IF sub-task.time_spent > 16h
THEN notify_manager("任务可能需要拆分")
- IF story.sub_tasks.all(status=Done)
THEN transition_story(Done)
Linear项目模板
# Linear项目设置
Labels:
Priority:
- P0-Urgent(当天必须完成)
- P1-High(本周必须完成)
- P2-Medium(本Sprint完成)
- P3-Low(Backlog)
Size:
- XS(<2小时)
- S(2-4小时)
- M(4-8小时)⭐ 推荐粒度
- L(1-2天)
- XL(>2天,需拆分)
Cycles:
duration: 1 week
cooldown: 1 day(Sprint回顾)
Automations:
- 当Issue标记为XL时,自动添加"needs-breakdown"标签
- 当Issue在In Progress超过2天,自动高亮提醒
12.2 度量模板
任务粒度健康度追踪表
| 周次 | 总任务数 | 平均粒度(h) | <4h占比 | 4-12h占比 | >12h占比 | 完成率 | 备注 |
|-----|---------|-----------|---------|----------|---------|-------|------|
| W1 | 45 | 6.2 | 15% | 72% | 13% | 89% | 基线 |
| W2 | 48 | 5.8 | 18% | 75% | 7% | 92% | 改善中 |
| W3 | 52 | 5.5 | 12% | 82% | 6% | 94% | 目标达成 |
健康度判断标准:
✅ 健康:4-12h占比 ≥ 70%,完成率 ≥ 90%
⚠️ 警告:4-12h占比 50-70%,或完成率 80-90%
❌ 需改进:4-12h占比 < 50%,或完成率 < 80%
估时准确率追踪表
| 任务ID | 预估(h) | 实际(h) | 偏差率 | 偏差原因 | 改进措施 |
|-------|--------|--------|-------|---------|---------|
| T-101 | 8 | 12 | +50% | 需求理解偏差 | 加强需求评审 |
| T-102 | 4 | 3 | -25% | 技术方案成熟 | 可作为参考基准 |
| T-103 | 8 | 8 | 0% | - | - |
膨胀系数计算:
团队膨胀系数 = Σ(实际工时) / Σ(预估工时)
如果膨胀系数 > 1.3,建议:
1. 在预估时乘以膨胀系数
2. 或者进行更细的前期拆解
12.3 团队引入路径:渐进式推行
将任务粒度优化引入团队不应"一刀切",而应采用渐进式推行策略。下图展示了从试点到全面推广的三阶段路径:先在小团队验证可行性,再扩展到更多团队,最后固化为组织标准。
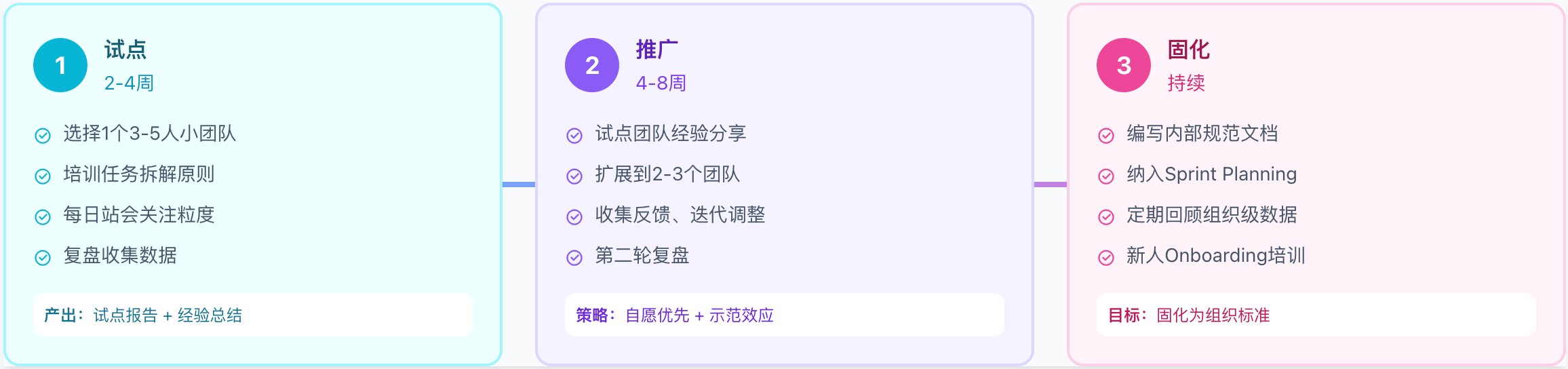
团队引入路径:渐进式推行
阶段一:试点(2-4周)
目标:在一个小团队验证可行性
试点团队选择标准:
团队Lead支持变革
团队成员技术能力中等以上
近期无紧急项目压力
阶段二:推广(4-8周)
目标:将试点经验复制到更多团队
推广策略:
自愿优先:优先推广到主动报名的团队
示范效应:邀请试点团队成员到其他团队分享
工具支撑:配套提供Jira/Linear模板
阶段三:固化(持续)
目标:将实践固化为组织标准
常见阻力与应对
12.4 Sprint Planning检查清单
在每次Sprint Planning会议中,使用以下清单验证任务拆解质量:
## Sprint Planning任务拆解检查清单
### 单个任务检查
- [ ] 任务粒度是否在4-12小时之间?
- [ ] 任务能否独立测试/验证?
- [ ] 验收标准是否明确?
- [ ] 是否有未解决的依赖或阻塞?
### Story级别检查
- [ ] 所有Sub-task加起来是否覆盖了Story的全部范围?
- [ ] Sub-task之间是否有重复或遗漏?
- [ ] Story是否符合INVEST原则?
### Sprint整体检查
- [ ] 总工时是否在团队容量的80%以内?(留Buffer)
- [ ] 是否有任务依赖形成"串行瓶颈"?
- [ ] 高风险任务是否安排在Sprint前期?
### 红线警告(发现即暂停)
- ⚠️ 单个任务 > 2天
- ⚠️ 任务无法独立演示
- ⚠️ "我先做完再拆"的借口
12.5 任务拆解模板(可直接复用)
功能开发任务拆解模板
## Feature: [功能名称]
### 背景
[为什么要做这个功能?用户价值是什么?]
### 验收标准
1. [标准1]
2. [标准2]
3. [标准3]
### 任务拆解
#### 准备阶段
- [ ] [T1] 技术方案评审(2h)
- [ ] [T2] 数据库设计评审(1h)
#### 开发阶段
- [ ] [T3] 实现XX接口(4h)
- [ ] [T4] 实现XX页面(6h)
- [ ] [T5] 编写单元测试(3h)
#### 验收阶段
- [ ] [T6] 联调测试(2h)
- [ ] [T7] Code Review修改(2h)
### 依赖关系
- T3 → T4(接口完成后才能对接页面)
- T4 → T5(功能完成后才能写测试)
### 风险识别
| 风险 | 概率 | 影响 | 应对 |
|-----|-----|-----|------|
| XX接口响应慢 | 中 | 高 | 提前联调 |
来源:
附录:参考文献与延伸阅读
理论基础
Amdahl定律与生产力陷阱
任务颗粒度系统研究
Brooks定律
《人月神话》Fred Brooks, 1975
大厂实践
阿里巴巴云效
腾讯TAPD
亚马逊Two-Pizza Teams
Google代码评审
字节跳动效能度量
华为研发管理
美团技术实践
拼多多任务拆解
心理学研究
AI协作与SDD
实操方法论
任务拆解算法
敏捷Scrum框架
职能差异
认知科学与组织行为
认知负荷理论
古德哈特定律
精益软件开发
精益七大浪费与流动效率
在制品限制(WIP Limits)
软件研发范式演进
群智范式与开源协作
Agentic AI与智能研发
效能度量体系
DORA与SPACE框架
DevData基准报告
效能度量实践
任务分解方法论
敏捷任务分解
注意力与中断研究
协作效能
微服务与系统设计
2023-2024最新研究
AI辅助开发效能研究
远程协作与任务管理
认知科学最新进展
Spec-Driven Development实践
研发效能新趋势
团队规模与效能


评论区